
Introduction
Summarize a text using the Bart Large CNN pre-trained model:
curl "https://api.nlpcloud.io/v1/bart-large-cnn/summarization" \
-H "Authorization: Token 4eC39HqLyjWDarjtT1zdp7dc" \
-H "Content-Type: application/json" \
-X POST \
-d '{"text":"One month after the United States began what has become a troubled rollout of a national COVID vaccination campaign, the effort is finally gathering real steam. Close to a million doses -- over 951,000, to be more exact -- made their way into the arms of Americans in the past 24 hours, the U.S. Centers for Disease Control and Prevention reported Wednesday. That s the largest number of shots given in one day since the rollout began and a big jump from the previous day, when just under 340,000 doses were given, CBS News reported. That number is likely to jump quickly after the federal government on Tuesday gave states the OK to vaccinate anyone over 65 and said it would release all the doses of vaccine it has available for distribution. Meanwhile, a number of states have now opened mass vaccination sites in an effort to get larger numbers of people inoculated, CBS News reported."}'
import nlpcloud
client = nlpcloud.Client("bart-large-cnn", "4eC39HqLyjWDarjtT1zdp7dc")
# Returns a json object.
client.summarization("""One month after the United States began what has become a
troubled rollout of a national COVID vaccination campaign, the effort is finally
gathering real steam. Close to a million doses -- over 951,000, to be more exact --
made their way into the arms of Americans in the past 24 hours, the U.S. Centers
for Disease Control and Prevention reported Wednesday. That s the largest number
of shots given in one day since the rollout began and a big jump from the
previous day, when just under 340,000 doses were given, CBS News reported.
That number is likely to jump quickly after the federal government on Tuesday
gave states the OK to vaccinate anyone over 65 and said it would release all
the doses of vaccine it has available for distribution. Meanwhile, a number
of states have now opened mass vaccination sites in an effort to get larger
numbers of people inoculated, CBS News reported.""")
require 'nlpcloud'
client = NLPCloud::Client.new('bart-large-cnn','4eC39HqLyjWDarjtT1zdp7dc')
# Returns a json object.
client.summarization("One month after the United States began what has become a
troubled rollout of a national COVID vaccination campaign, the effort is finally
gathering real steam. Close to a million doses -- over 951,000, to be more exact --
made their way into the arms of Americans in the past 24 hours, the U.S. Centers
for Disease Control and Prevention reported Wednesday. That s the largest number
of shots given in one day since the rollout began and a big jump from the
previous day, when just under 340,000 doses were given, CBS News reported.
That number is likely to jump quickly after the federal government on Tuesday
gave states the OK to vaccinate anyone over 65 and said it would release all
the doses of vaccine it has available for distribution. Meanwhile, a number
of states have now opened mass vaccination sites in an effort to get larger
numbers of people inoculated, CBS News reported.")
package main
import (
"net/http"
"github.com/nlpcloud/nlpcloud-go"
)
func main() {
client := nlpcloud.NewClient(&http.Client{}, nlpcloud.ClientParams{
Model:"bart-large-cnn", Token:"4eC39HqLyjWDarjtT1zdp7dc", GPU:false, Lang:"", Async:false})
summary, err := client.Summarization(nlpcloud.SummarizationParams{Text: "One month after the United States began what has become a
troubled rollout of a national COVID vaccination campaign, the effort is finally
gathering real steam. Close to a million doses -- over 951,000, to be more exact --
made their way into the arms of Americans in the past 24 hours, the U.S. Centers
for Disease Control and Prevention reported Wednesday. That s the largest number
of shots given in one day since the rollout began and a big jump from the
previous day, when just under 340,000 doses were given, CBS News reported.
That number is likely to jump quickly after the federal government on Tuesday
gave states the OK to vaccinate anyone over 65 and said it would release all
the doses of vaccine it has available for distribution. Meanwhile, a number
of states have now opened mass vaccination sites in an effort to get larger
numbers of people inoculated, CBS News reported."})
...
}
const NLPCloudClient = require('nlpcloud');
const client = new NLPCloudClient({model:'bart-large-cnn', token:'4eC39HqLyjWDarjtT1zdp7dc'})
// Returns an Axios promise with the results.
// In case of success, results are contained in `response.data`.
// In case of failure, you can retrieve the status code in `err.response.status`
// and the error message in `err.response.data.detail`.
client.summarization({text:`One month after the United States began what has become a
troubled rollout of a national COVID vaccination campaign, the effort is finally
gathering real steam. Close to a million doses -- over 951,000, to be more exact --
made their way into the arms of Americans in the past 24 hours, the U.S. Centers
for Disease Control and Prevention reported Wednesday. That s the largest number
of shots given in one day since the rollout began and a big jump from the
previous day, when just under 340,000 doses were given, CBS News reported.
That number is likely to jump quickly after the federal government on Tuesday
gave states the OK to vaccinate anyone over 65 and said it would release all
the doses of vaccine it has available for distribution. Meanwhile, a number
of states have now opened mass vaccination sites in an effort to get larger
numbers of people inoculated, CBS News reported.`})
.then(function (response) {
console.log(response.data);
})
.catch(function (err) {
console.error(err.response.status);
console.error(err.response.data.detail);
});
require 'vendor/autoload.php';
use NLPCloud\NLPCloud;
$client = new \NLPCloud\NLPCloud('bart-large-cnn','4eC39HqLyjWDarjtT1zdp7dc');
# Returns a json object.
echo json_encode($client->summarization('One month after the United States began what has become a
troubled rollout of a national COVID vaccination campaign, the effort is finally
gathering real steam. Close to a million doses -- over 951,000, to be more exact --
made their way into the arms of Americans in the past 24 hours, the U.S. Centers
for Disease Control and Prevention reported Wednesday. That s the largest number
of shots given in one day since the rollout began and a big jump from the
previous day, when just under 340,000 doses were given, CBS News reported.
That number is likely to jump quickly after the federal government on Tuesday
gave states the OK to vaccinate anyone over 65 and said it would release all
the doses of vaccine it has available for distribution. Meanwhile, a number
of states have now opened mass vaccination sites in an effort to get larger
numbers of people inoculated, CBS News reported.'));
Summarize a text using the Bart Large CNN pre-trained model on GPU:
curl "https://api.nlpcloud.io/v1/gpu/bart-large-cnn/summarization" \
-H "Authorization: Token 4eC39HqLyjWDarjtT1zdp7dc" \
-H "Content-Type: application/json" \
-X POST \
-d '{"text":"One month after the United States began what has become a troubled rollout of a national COVID vaccination campaign, the effort is finally gathering real steam. Close to a million doses -- over 951,000, to be more exact -- made their way into the arms of Americans in the past 24 hours, the U.S. Centers for Disease Control and Prevention reported Wednesday. That s the largest number of shots given in one day since the rollout began and a big jump from the previous day, when just under 340,000 doses were given, CBS News reported. That number is likely to jump quickly after the federal government on Tuesday gave states the OK to vaccinate anyone over 65 and said it would release all the doses of vaccine it has available for distribution. Meanwhile, a number of states have now opened mass vaccination sites in an effort to get larger numbers of people inoculated, CBS News reported."}'
import nlpcloud
client = nlpcloud.Client("bart-large-cnn", "4eC39HqLyjWDarjtT1zdp7dc", gpu=True)
# Returns a json object.
client.summarization("""One month after the United States began what has become a
troubled rollout of a national COVID vaccination campaign, the effort is finally
gathering real steam. Close to a million doses -- over 951,000, to be more exact --
made their way into the arms of Americans in the past 24 hours, the U.S. Centers
for Disease Control and Prevention reported Wednesday. That s the largest number
of shots given in one day since the rollout began and a big jump from the
previous day, when just under 340,000 doses were given, CBS News reported.
That number is likely to jump quickly after the federal government on Tuesday
gave states the OK to vaccinate anyone over 65 and said it would release all
the doses of vaccine it has available for distribution. Meanwhile, a number
of states have now opened mass vaccination sites in an effort to get larger
numbers of people inoculated, CBS News reported.""")
require 'nlpcloud'
client = NLPCloud::Client.new('bart-large-cnn','4eC39HqLyjWDarjtT1zdp7dc', gpu: true)
# Returns a json object.
client.summarization("One month after the United States began what has become a
troubled rollout of a national COVID vaccination campaign, the effort is finally
gathering real steam. Close to a million doses -- over 951,000, to be more exact --
made their way into the arms of Americans in the past 24 hours, the U.S. Centers
for Disease Control and Prevention reported Wednesday. That s the largest number
of shots given in one day since the rollout began and a big jump from the
previous day, when just under 340,000 doses were given, CBS News reported.
That number is likely to jump quickly after the federal government on Tuesday
gave states the OK to vaccinate anyone over 65 and said it would release all
the doses of vaccine it has available for distribution. Meanwhile, a number
of states have now opened mass vaccination sites in an effort to get larger
numbers of people inoculated, CBS News reported.")
package main
import (
"net/http"
"github.com/nlpcloud/nlpcloud-go"
)
func main() {
client := nlpcloud.NewClient(&http.Client{}, nlpcloud.ClientParams{
Model:"bart-large-cnn", Token:"4eC39HqLyjWDarjtT1zdp7dc", GPU:true, Lang:"", Async:false})
summary, err := client.Summarization(nlpcloud.SummarizationParams{Text: "One month after the United States began what has become a
troubled rollout of a national COVID vaccination campaign, the effort is finally
gathering real steam. Close to a million doses -- over 951,000, to be more exact --
made their way into the arms of Americans in the past 24 hours, the U.S. Centers
for Disease Control and Prevention reported Wednesday. That s the largest number
of shots given in one day since the rollout began and a big jump from the
previous day, when just under 340,000 doses were given, CBS News reported.
That number is likely to jump quickly after the federal government on Tuesday
gave states the OK to vaccinate anyone over 65 and said it would release all
the doses of vaccine it has available for distribution. Meanwhile, a number
of states have now opened mass vaccination sites in an effort to get larger
numbers of people inoculated, CBS News reported."})
...
}
const NLPCloudClient = require('nlpcloud');
const client = new NLPCloudClient({model:'bart-large-cnn', token:'4eC39HqLyjWDarjtT1zdp7dc', gpu:true})
// Returns an Axios promise with the results.
// In case of success, results are contained in `response.data`.
// In case of failure, you can retrieve the status code in `err.response.status`
// and the error message in `err.response.data.detail`.
client.summarization({text:`One month after the United States began what has become a
troubled rollout of a national COVID vaccination campaign, the effort is finally
gathering real steam. Close to a million doses -- over 951,000, to be more exact --
made their way into the arms of Americans in the past 24 hours, the U.S. Centers
for Disease Control and Prevention reported Wednesday. That s the largest number
of shots given in one day since the rollout began and a big jump from the
previous day, when just under 340,000 doses were given, CBS News reported.
That number is likely to jump quickly after the federal government on Tuesday
gave states the OK to vaccinate anyone over 65 and said it would release all
the doses of vaccine it has available for distribution. Meanwhile, a number
of states have now opened mass vaccination sites in an effort to get larger
numbers of people inoculated, CBS News reported.`})
.then(function (response) {
console.log(response.data);
})
.catch(function (err) {
console.error(err.response.status);
console.error(err.response.data.detail);
});
require 'vendor/autoload.php';
use NLPCloud\NLPCloud;
$client = new \NLPCloud\NLPCloud('bart-large-cnn','4eC39HqLyjWDarjtT1zdp7dc', True);
# Returns a json object.
echo json_encode($client->summarization('One month after the United States began what has become a
troubled rollout of a national COVID vaccination campaign, the effort is finally
gathering real steam. Close to a million doses -- over 951,000, to be more exact --
made their way into the arms of Americans in the past 24 hours, the U.S. Centers
for Disease Control and Prevention reported Wednesday. That s the largest number
of shots given in one day since the rollout began and a big jump from the
previous day, when just under 340,000 doses were given, CBS News reported.
That number is likely to jump quickly after the federal government on Tuesday
gave states the OK to vaccinate anyone over 65 and said it would release all
the doses of vaccine it has available for distribution. Meanwhile, a number
of states have now opened mass vaccination sites in an effort to get larger
numbers of people inoculated, CBS News reported.'));
Output:
{
"summary_text": "Over 951,000 doses were given in the past 24 hours.
That's the largest number of shots given in one day since the rollout began.
That number is likely to jump quickly after the federal government gave
states the OK to vaccinate anyone over 65. A number of states have now
opened mass vaccination sites."
}
Welcome to the NLP Cloud API documentation.
Here is the list of use cases you can perform on the NLP Cloud API:
| Use Case | Model Used |
|---|---|
| Automatic Speech Recognition/Speech to Text: extract text from an audio or video file (see endpoint) | We use OpenAI's Whisper Large for speech to text in 97 languages. |
| Chatbot/Conversational AI: create an advanced chatbot (see endpoint) | We use in-house NLP Cloud models called ChatDolphin, and Fine-tuned LLaMA 3 70B. We also use Yi 34B by 01 AI, Dolphin Yi 34B by Eric Hartford, Mixtral 8x7B by Mistral AI, and Dolphin Mixtral 8x7B by Eric Hartford. This endpoint can leverage our multilingual add-on. |
| Classification: send a text, and let the model categorize the text for you in many languages (as an option you can give the candidate categories you want to assess) (see endpoint) | We use the Bart Large MNLI Yahoo Answers by Joe Davison, XLM Roberta Large XNLI by Joe Davison, an in-house NLP Cloud model called Fine-tuned LLaMA 3 70B, Yi 34B by 01 AI, and Mixtral 8x7B by Mistral AI. This endpoint can leverage our multilingual add-on. |
| Code Generation: generate source code out of a simple instruction, in any programming language (see endpoint) | We use in-house NLP Cloud models called ChatDolphin and Fine-tuned LLaMA 3 70B. We also use Dolphin Yi 34B by Eric Hartford and Dolphin Mixtral 8x7B by Eric Hartford. |
| Embeddings: calculate embeddings from a list of texts, in many languages (see endpoint) | We use Paraphrase Multilingual MPNet Base V2. |
| Headline Generation: send a text, and get a one sentence headline summarizing everything, in many languages (see endpoint) | We use T5 Base EN Generate Headline by Michal Pleban. This endpoint can leverage our multilingual add-on. |
| Grammar And Spelling Correction: remove the grammar and spelling errors from your text (see endpoint) | We use in-house NLP Cloud models called ChatDolphin, and Fine-tuned LLaMA 3 70B. We also use Dolphin Yi 34B by Eric Hartford, and Dolphin Mixtral 8x7B by Eric Hartford. This endpoint can leverage our multilingual add-on. |
| Image Generation: generate an image out of a simple text instruction (see endpoint) | We use Stable Diffusion. This endpoint can leverage our multilingual add-on |
| Intent Classification: detect the intent hidden behind a text (see endpoint) | We use in-house NLP Cloud models called ChatDolphin, and Fine-tuned LLaMA 3 70B. We also use Dolphin Yi 34B by Eric Hartford and Dolphin Mixtral 8x7B by Eric Hartford. This endpoint can leverage our multilingual add-on. |
| Keywords and Keyphrases Extraction: extract the main ideas in a text (see endpoint) | We use an in-house NLP Cloud model called Fine-tuned LLaMA 3 70B. This endpoint can leverage our multilingual add-on. |
| Language Detection: detect one or several languages from a text (see endpoint) | We use Python's Langdetect library. |
| Lemmatization: extract lemmas from a text, in many languages (see endpoint) | All the large spaCy models are available (15 languages) and Megagon Lab's Ginza for Japanese |
| Named Entity Recognition (NER): extract and tag relevant entities from a text, like name, company, country... in many languages (see endpoint) | All the large spaCy models are available (15 languages), and Megagon Lab's Ginza for Japanese, and generative models with PyTorch and Jax. |
| Noun Chunks Extraction: extract noun chunks from a text, in many languages (see endpoint) | All the large spaCy models are available (15 languages) and Megagon Lab's Ginza for Japanese |
| Paraphrasing and rewriting: send a text, and get a rephrased version that has the same meaning but with new words (see endpoint) | We use an in-house NLP Cloud model called Fine-tuned LLaMA 3 70B. This endpoint can leverage our multilingual add-on. |
| Part-Of-Speech (POS) tagging: assign parts of speech to each word of your text, in many languages (see endpoint) | All the large spaCy models are available (15 languages) and Megagon Lab's Ginza for Japanese |
| Question answering: ask questions about anything (as an option you can give a context and ask specific questions about this context) in many languages (see endpoint) | We use an in-house NLP Cloud models called ChatDolphin, and Fine-tuned LLaMA 3 70B. We also use Dolphin Yi 34B by Eric Hartford, and Dolphin Mixtral 8x7B by Eric Hartford. This endpoint can leverage our multilingual add-on. |
| Semantic Search: search your own data, in many languages (see endpoint) | Create your own semantic search model. |
| Semantic Similarity: detect whether 2 pieces of text have the same meaning or not, in many languages (see endpoint) | We use Paraphrase Multilingual MPNet Base V2. |
| Sentiment analysis: determine whether a text is rather positive or negative or detect emotions, in many languages (see endpoint) | We use DistilBERT Base Uncased Finetuned SST-2 and DistilBERT Base Uncased Emotion. This endpoint can leverage our multilingual add-on. |
| Speech Synthesis/Text To Speech: generate audio out of text (see endpoint) | We use Speech T5 by Microsoft to synthesize voice in English |
| Summarization: send a text, and get a smaller text keeping essential information only, in many languages (see endpoint) | We use Bart Large CNN by Meta, in-house NLP Cloud models called ChatDolphin and Fine-tuned LLaMA 3 70B, Dolphin Yi 34B by Eric Hartford, and Dolphin Mixtral 8x7B by Eric Hartford. This endpoint can leverage our multilingual add-on. |
| Text generation: achieve any AI use case using generative models, in many languages (see endpoint) | We use in-house NLP Cloud models called ChatDolphin, and Fine-tuned LLaMA 3 70B. We also use Yi 34B by 01 AI, Dolphin Yi 34B by Eric Hartford, Mixtral 8x7B by Mistral AI, and Dolphin Mixtral 8x7B by Eric Hartford. This endpoint can leverage our multilingual add-on. |
| Tokenization: extract tokens from a text, in many languages (see endpoint) | All the large spaCy models are available (15 languages) and Megagon Lab's Ginza for Japanese |
| Translation: translate text from one language to another (see endpoint) | We use NLLB 200 3.3B by Meta for translation in 200 languages |
If not done yet, please retrieve an API key from your dashboard and don't hesitate to test our models on the playground. Also do not hesitate to contact us if needed: [email protected].
If you need to process non-English languages, we encourage you to either use our multilingual add-on or use a model that natively supports your language.
See on the right a full example about summarizing block of text, using Facebook's Bart Large CNN pre-trained model, both on CPU and GPU. And the same example below using Postman:
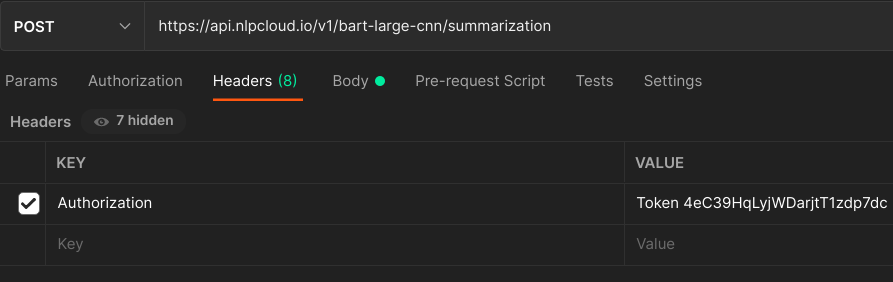
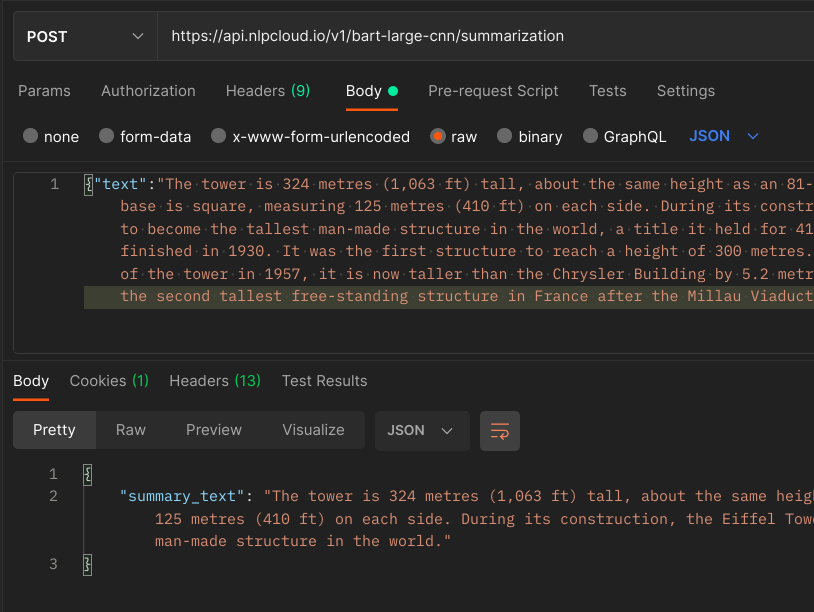
Not a programmer? See this tutorial about using NLP Cloud with the Bubble.io no-code platform.
You can fine-tune your own models. You can also upload your own custom models in your dashboard.
In addition to this documentation, you can also read this introduction article and watch this introduction video.
We welcome every feedbacks about the API, the documentation, or the client libraries. Please let us know!
Set Up
Client Installation
If you are using one of our client libraries, here is how to install them.
Python
Install with pip.
pip install nlpcloud
More details on the source repo: https://github.com/nlpcloud/nlpcloud-python
Ruby
Install with gem.
gem install nlpcloud
More details on the source repo: https://github.com/nlpcloud/nlpcloud-ruby
Go
Install with go install.
go install github.com/nlpcloud/nlpcloud-go
More details on the source repo: https://github.com/nlpcloud/nlpcloud-go
Node.js
Install with NPM.
npm install nlpcloud --save
More details on the source repo: https://github.com/nlpcloud/nlpcloud-js
PHP
Install with Composer.
Create a composer.json file containing at least the following:
{"require": {"nlpcloud/nlpcloud-client": "*"}}
Then launch the following:
composer install
More details on the source repo: https://github.com/nlpcloud/nlpcloud-php
Authentication
Replace
with your token:
curl "https://api.nlpcloud.io/v1/<model>/<endpoint>" \
-H "Authorization: Token <token>"
import nlpcloud
client = nlpcloud.Client("<model>", "<token>")
require 'nlpcloud'
client = NLPCloud::Client.new('<model>','<token>')
package main
import (
"net/http"
"github.com/nlpcloud/nlpcloud-go"
)
func main() {
client := nlpcloud.NewClient(&http.Client, "<model>", "<token>", false, "")
...
}
const NLPCloudClient = require('nlpcloud');
const client = new NLPCloudClient({model:'<model>', token:'<token>'})
use NLPCloud\NLPCloud;
$client = new \NLPCloud\NLPCloud('<model>','<token>');
Add your API key after the Token keyword in an Authorization header. You should include this header in all your requests: Authorization: Token <token>. Alternatively you can also use Bearer instead of Token: Authorization: Bearer <token>.
Here is an example using Postman (Postman is automatically adding headers to the requests. You should at least keep the Host header, otherwise you will get a 400 error.):
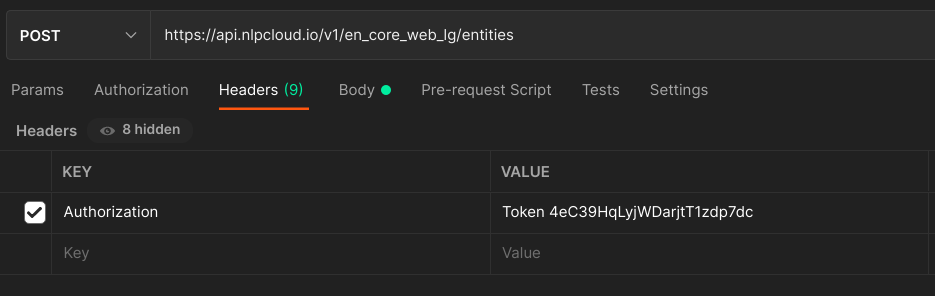
If not done yet, please get an API key in your dashboard.
All API requests must be made over HTTPS. Calls made over plain HTTP will fail. API requests without authentication will also fail.
Versioning
Replace
with the right API version:
curl "https://api.nlpcloud.io/<version>/<model>/<endpoint>"
# The latest API version is automatically set by the library.
# The latest API version is automatically set by the library.
// The latest API version is automatically set by the library.
// The latest API version is automatically set by the library.
// The latest API version is automatically set by the library.
The latest API version is v1.
The API version comes right after the domain name, and before the model name.
Encoding
POST JSON data:
curl "https://api.nlpcloud.io/v1/<model>/<endpoint>" \
-H "Content-Type: application/json" \
-X POST \
-d '{"text":"John Doe has been working for Microsoft in Seattle since 1999."}'
# Encoding is automatically handled by the library.
# Encoding is automatically handled by the library.
// Encoding is automatically handled by the library.
// Encoding is automatically handled by the library.
// Encoding is automatically handled by the library.
You should send JSON encoded data in POST requests.
Don't forget to set the content-type accordingly: "Content-Type: application/json".
Here is an example using Postman:
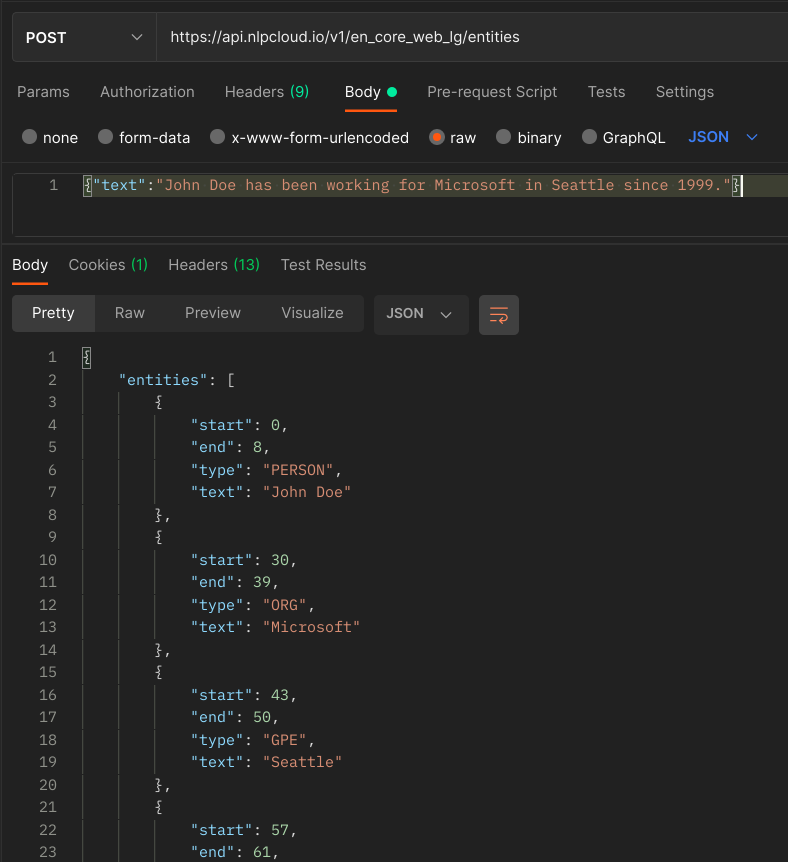
Put your JSON data in Body > raw. Note that if your text contains double quotes (") you will need to escape them (using \") in order for your JSON to be properly decoded. This is not needed when using a client library.
Models
Replace
with the right pre-trained model:
curl "https://api.nlpcloud.io/v1/<model>/<endpoint>"
# Set the model during client initialization.
client = nlpcloud.Client("<model>", "<token>")
client = NLPCloud::Client.new('<model>','<token>')
client := nlpcloud.NewClient(&http.Client, "<model>", "<token>", false, "")
const client = new NLPCloudClient({model:'<model>',token:'<token>'})
$client = new \NLPCloud\NLPCloud('<model>','<token>');
Example: pre-trained spaCy's en_core_web_lg model for Named Entity Recognition (NER):
curl "https://api.nlpcloud.io/v1/en_core_web_lg/entities"
client = nlpcloud.Client("en_core_web_lg", "<token>")
client = NLPCloud::Client.new('en_core_web_lg','<token>')
client := nlpcloud.NewClient(&http.Client, "en_core_web_lg", "<token>", false, "")
const client = new NLPCloudClient({model:'en_core_web_lg',token:'<token>'})
$client = new \NLPCloud\NLPCloud('en_core_web_lg','<your token>');
Example: your private spaCy model with ID 7894 for Named Entity Recognition (NER):
curl "https://api.nlpcloud.io/v1/custom-model/7894/entities"
client = nlpcloud.Client("custom-model/7894", "<token>")
client = NLPCloud::Client.new('custom-model/7894','<token>')
client := nlpcloud.NewClient(&http.Client, "custom-model/7894", "<token>", false, "")
const client = new NLPCloudClient({model:'custom-model/7894',token:'<token>'})
$client = new \NLPCloud\NLPCloud('custom-model/7894','<your token>');
You can use many pre-trained models (see below) for all kinds of AI use cases like sentiment analysis, classification, summarization, text generation, and much more.
You can also use your own private models, in 2 different ways:
- Train/fine-tune and deploy a private model (it happens here in your dashboard)
- Upload and deploy a private model (it happens here in your dashboard).
In case of a private model, your private API endpoint appears in your dashboard once the fine-tuning is finished, or the model upload is finished.
Here is an example on the right performing Named Entity Recognition (NER) with spaCy's pre-trained en_core_web_lg model, and another example doing the same thing with your own private spaCy model with ID 7894.
Models List
Here is a comprehensive list of all the pre-trained models supported by the NLP Cloud API:
| Name | Description | Libraries |
|---|---|---|
| en_core_web_lg: spaCy's English Large | See on spaCy | spaCy v3 |
| fr_core_news_lg: spaCy's French Large | See on spaCy | spaCy v3 |
| zh_core_web_lg: spaCy's Chinese Large | See on spaCy | spaCy v3 |
| da_core_news_lg: spaCy's Danish Large | See on spaCy | spaCy v3 |
| nl_core_news_lg: spaCy's Dutch Large | See on spaCy | spaCy v3 |
| de_core_news_lg: spaCy's German Large | See on spaCy | spaCy v3 |
| el_core_news_lg: spaCy's Greek Large | See on spaCy | spaCy v3 |
| it_core_news_lg: spaCy's Italian Large | See on spaCy | spaCy v3 |
| ja_ginza_electra: Megagon Lab's Ginza | See on Github | spaCy v3 |
| ja_core_news_lg: spaCy's Japanese Large | See on spaCy | spaCy v3 |
| lt_core_news_lg: spaCy's Lithuanian Large | See on spaCy | spaCy v3 |
| nb_core_news_lg: spaCy's Norwegian okmål Large | See on spaCy | spaCy v3 |
| pl_core_news_lg: spaCy's Polish Large | See on spaCy | spaCy v3 |
| pt_core_news_lg: spaCy's Portuguese Large | See on spaCy | spaCy v3 |
| ro_core_news_lg: spaCy's Romanian Large | See on spaCy | spaCy v3 |
| es_core_news_lg: spaCy's Spanish Large | See on spaCy | spaCy v3 |
| bart-large-mnli-yahoo-answers: Joe Davison's Bart Large MNLI Yahoo Answers | See on Hugging Face | PyTorch / Transformers |
| xlm-roberta-large-xnli: Joe Davison's XLM Roberta Large XNLI | See on Hugging Face | PyTorch / Transformers |
| bart-large-cnn: Meta's Bart Large CNN | See on Hugging Face | PyTorch / Transformers |
| t5-base-en-generate-headline: Michal Pleban's T5 Base EN Generate Headline | See on Hugging Face | PyTorch / Transformers |
| distilbert-base-uncased-finetuned-sst-2-english: Distilbert Finetuned SST 2 | See on Hugging Face | PyTorch / Transformers |
| distilbert-base-uncased-emotion: Distilbert Emotion | See on Hugging Face | PyTorch / Transformers |
| finetuned-llama-3-70b: Fine-tuned LLaMA 3 70B | A fine-tuned version of LLaMA 3 70B | PyTorch |
| chatdolphin: ChatDolphin | An in-house NLP Cloud base generative model | PyTorch |
| dolphin-yi-34b: Eric Hartford's Dolphin Yi 34B | See on Hugging Face | PyTorch |
| dolphin-mixtral-8x7b: Eric Hartford's Dolphin Mixtral 8x7B | See on Hugging Face | PyTorch |
| nllb-200-3-3b: Facebook's NLLB 200 3.3B | See on Hugging Face | PyTorch / Transformers |
| paraphrase-multilingual-mpnet-base-v2: Paraphrase Multilingual MPNet Base V2 | See on Hugging Face | PyTorch / Sentence Transformers |
| python-langdetect: Python LangDetect library | See on Pypi | LangDetect |
| speech-t5: Microsoft's Speech T5 | See on Microsoft's repo | Pytorch / Transformers |
| stable-diffusion: Stability AI's Stable Diffusion XL model | See on Hugging Face | PyTorch / Diffusers |
| whisper: OpenAI's Whisper Large | See on OpenAI's repo | PyTorch |
Train/Fine-Tune Your Own Model
See the dedicated fine-tuning section for more details.
Upload Your Own Model Based On HF Transformers
Save your model to disk
model.save_pretrained('saved_model')
You can use your own models based on the Hugging Face Transformers framework.
If your model is publicly available on Hugging Face, you can simply send us the link to the Hugging Face repository.
Alternatively, here are the steps you should follow:
Save your model to disk in a saved_model directory using the .save_pretrained method: model.save_pretrained('saved_model').
Then compress the newly created saved_model directory using Zip.
Finally, upload your Zip file in your dashboard.
If your model comes with a custom script, you can send this script to [email protected], together with any relevant instruction necessary to make your model run. If your model must support custom input or output formats, please let us know so we can adapt the API signature. If we have questions we will let you know.
If you experience difficulties, please contact us so we can assist.
Upload Your spaCy Model
Export in Python script:
nlp.to_disk("/path")
Package:
python -m spacy package /path/to/exported/model /path/to/packaged/model
Archive as .tar.gz:
# Go to /path/to/packaged/model
python setup.py sdist
Or archive as .whl:
# Go to /path/to/packaged/model
python setup.py bdist_wheel
You can use your own spaCy models.
Upload your custom spaCy model in your dashboard, but first you need to export it and package it as a Python module.
Here is what you should do:
- Export your model to disk using the spaCy
to_disk("/path")command. - Package your exported model using the
spacy packagecommand. - Archive your packaged model either as a
.tar.gzarchive usingpython setup.py sdistor as a Python wheel usingpython setup.py bdist_wheel(both formats are accepted). - Retrieve you archive in the newly created
distfolder and upload it in your dashboard.
If your model comes with a custom script, you can send this script to [email protected], together with any relevant instruction necessary to make your model run. If your model must support custom input or output formats, please let us know so we can adapt the API signature. If we have questions we will let you know.
If you experience difficulties, please contact us so we can assist.
Upload Models Based On Other Frameworks
You might deploy NLP models not based on spaCy or Hugging Face Transformers.
Please contact us so we can advise.
GPU
Text classification with Bart Large MNLI Yahoo Answers on GPU
curl "https://api.nlpcloud.io/v1/gpu/bart-large-mnli-yahoo-answers/classification" \
-H "Authorization: Token <token>" \
-H "Content-Type: application/json" \
-X POST \
-d '{
"text":"John Doe is a Go Developer at Google. He has been working there for 10 years and has been awarded employee of the year",
"labels":["job", "nature", "space"],
"multi_class": true
}'
import nlpcloud
client = nlpcloud.Client("bart-large-mnli-yahoo-answers", "<token>", gpu=True)
# Returns a json object.
client.classification("""John Doe is a Go Developer at Google.
He has been working there for 10 years and has been
awarded employee of the year.""",
labels=["job", "nature", "space"],
multi_class=True)
require 'nlpcloud'
client = NLPCloud::Client.new('bart-large-mnli-yahoo-answers','<token>', gpu: true)
# Returns a json object.
client.classification("John Doe is a Go Developer at Google.
He has been working there for 10 years and has been
awarded employee of the year.",
labels: ["job", "nature", "space"],
multi_class: true)
import (
"net/http"
"github.com/nlpcloud/nlpcloud-go"
)
func newTrue() *bool {
b := true
return &b
}
func main() {
client := nlpcloud.NewClient(&http.Client{}, nlpcloud.ClientParams{Model:"bart-large-mnli-yahoo-answers", Token:"<token>",
GPU:true, Lang:"", Async:false})
// Returns a Classification struct.
classes, err := client.Classification(nlpcloud.ClassificationParams{
Text: `John Doe is a Go Developer at Google. He has been working there for
10 years and has been awarded employee of the year.`,
Labels: []string{"job", "nature", "space"},
MultiClass: newTrue(),
})
...
}
const NLPCloudClient = require('nlpcloud');
const client = new NLPCloudClient({model:'bart-large-mnli-yahoo-answers', token:'<token>', gpu:true})
// Returns an Axios promise with the results.
// In case of success, results are contained in `response.data`.
// In case of failure, you can retrieve the status code in `err.response.status`
// and the error message in `err.response.data.detail`.
client.classification({text:`John Doe is a Go Developer at Google.
He has been working there for 10 years and has been
awarded employee of the year.`,
labels:['job', 'nature', 'space'],
multiClass:true}).then(function (response) {
console.log(response.data);
})
.catch(function (err) {
console.error(err.response.status);
console.error(err.response.data.detail);
});
require 'vendor/autoload.php';
use NLPCloud\NLPCloud;
$client = new \NLPCloud\NLPCloud('bart-large-mnli-yahoo-answers','<token>', True);
# Returns a json object.
echo json_encode($client->classification("John Doe is a Go Developer at Google.
He has been working there for 10 years and has been
awarded employee of the year.",
array("job", "nature", "space"),
True));
We recommend that you subscribe to a GPU plan for better performance, especially for real-time applications or for computation-intensive generative models.
In order to use a GPU, simply add gpu in the endpoint URL, after the API version, and before the name of the model.
For example if you want to use the Bart Large MNLI Yahoo Answers classification model on a GPU, you should use the following endpoint:
https://api.nlpcloud.io/v1/gpu/bart-large-mnli-yahoo-answers/classification
See a full example on the right.
Multilingual Add-On
Example: performing French summarization with Bart Large CNN:
curl "https://api.nlpcloud.io/v1/fra_Latn/bart-large-cnn/summarization" \
-H "Authorization: Token <token>" \
-H "Content-Type: application/json" \
-X POST -d '{
"text":"Sur des images aériennes, prises la veille par un vol de surveillance
de la Nouvelle-Zélande, la côte d’une île est bordée d’arbres passés du vert
au gris sous l’effet des retombées volcaniques. On y voit aussi des immeubles
endommagés côtoyer des bâtiments intacts. « D’après le peu d’informations
dont nous disposons, l’échelle de la dévastation pourrait être immense,
spécialement pour les îles les plus isolées », avait déclaré plus tôt
Katie Greenwood, de la Fédération internationale des sociétés de la Croix-Rouge.
Selon l’Organisation mondiale de la santé (OMS), une centaine de maisons ont
été endommagées, dont cinquante ont été détruites sur l’île principale de
Tonga, Tongatapu. La police locale, citée par les autorités néo-zélandaises,
a également fait état de deux morts, dont une Britannique âgée de 50 ans,
Angela Glover, emportée par le tsunami après avoir essayé de sauver les chiens
de son refuge, selon sa famille."
}'
import nlpcloud
client = nlpcloud.Client("bart-large-cnn", "<token>", lang="fra_Latn")
# Returns a json object.
client.summarization("""Sur des images aériennes, prises la veille par un vol de surveillance
de la Nouvelle-Zélande, la côte d’une île est bordée d’arbres passés du vert
au gris sous l’effet des retombées volcaniques. On y voit aussi des immeubles
endommagés côtoyer des bâtiments intacts. « D’après le peu d’informations
dont nous disposons, l’échelle de la dévastation pourrait être immense,
spécialement pour les îles les plus isolées », avait déclaré plus tôt
Katie Greenwood, de la Fédération internationale des sociétés de la Croix-Rouge.
Selon l’Organisation mondiale de la santé (OMS), une centaine de maisons ont
été endommagées, dont cinquante ont été détruites sur l’île principale de
Tonga, Tongatapu. La police locale, citée par les autorités néo-zélandaises,
a également fait état de deux morts, dont une Britannique âgée de 50 ans,
Angela Glover, emportée par le tsunami après avoir essayé de sauver les chiens
de son refuge, selon sa famille.""")
require 'nlpcloud'
client = NLPCloud::Client.new('bart-large-cnn','<token>', lang: 'fr')
# Returns a json object.
client.summarization("Sur des images aériennes, prises la veille par un vol de surveillance
de la Nouvelle-Zélande, la côte d’une île est bordée d’arbres passés du vert
au gris sous l’effet des retombées volcaniques. On y voit aussi des immeubles
endommagés côtoyer des bâtiments intacts. « D’après le peu d’informations
dont nous disposons, l’échelle de la dévastation pourrait être immense,
spécialement pour les îles les plus isolées », avait déclaré plus tôt
Katie Greenwood, de la Fédération internationale des sociétés de la Croix-Rouge.
Selon l’Organisation mondiale de la santé (OMS), une centaine de maisons ont
été endommagées, dont cinquante ont été détruites sur l’île principale de
Tonga, Tongatapu. La police locale, citée par les autorités néo-zélandaises,
a également fait état de deux morts, dont une Britannique âgée de 50 ans,
Angela Glover, emportée par le tsunami après avoir essayé de sauver les chiens
de son refuge, selon sa famille.")
import (
"net/http"
"github.com/nlpcloud/nlpcloud-go"
)
func main() {
client := nlpcloud.NewClient(&http.Client{}, nlpcloud.ClientParams{Model:"bart-large-cnn", Token:"<token>",
GPU:false, Lang:"fra_Latn", Async:false})
// Returns a Summarization struct.
summary, err := client.Summarization(nlpcloud.SummarizationParams{
Text: `Sur des images aériennes, prises la veille par un vol de surveillance
de la Nouvelle-Zélande, la côte d’une île est bordée d’arbres passés du vert
au gris sous l’effet des retombées volcaniques. On y voit aussi des immeubles
endommagés côtoyer des bâtiments intacts. « D’après le peu d’informations
dont nous disposons, l’échelle de la dévastation pourrait être immense,
spécialement pour les îles les plus isolées », avait déclaré plus tôt
Katie Greenwood, de la Fédération internationale des sociétés de la Croix-Rouge.
Selon l’Organisation mondiale de la santé (OMS), une centaine de maisons ont
été endommagées, dont cinquante ont été détruites sur l’île principale de
Tonga, Tongatapu. La police locale, citée par les autorités néo-zélandaises,
a également fait état de deux morts, dont une Britannique âgée de 50 ans,
Angela Glover, emportée par le tsunami après avoir essayé de sauver les chiens
de son refuge, selon sa famille.`,
})
...
}
const NLPCloudClient = require('nlpcloud');
const client = new NLPCloudClient({model:'bart-large-cnn','<token>', lang:'fr'})
// Returns an Axios promise with the results.
// In case of success, results are contained in `response.data`.
// In case of failure, you can retrieve the status code in `err.response.status`
// and the error message in `err.response.data.detail`.
client.summarization({text:`Sur des images aériennes, prises la veille par un vol de surveillance
de la Nouvelle-Zélande, la côte d’une île est bordée d’arbres passés du vert
au gris sous l’effet des retombées volcaniques. On y voit aussi des immeubles
endommagés côtoyer des bâtiments intacts. « D’après le peu d’informations
dont nous disposons, l’échelle de la dévastation pourrait être immense,
spécialement pour les îles les plus isolées », avait déclaré plus tôt
Katie Greenwood, de la Fédération internationale des sociétés de la Croix-Rouge.
Selon l’Organisation mondiale de la santé (OMS), une centaine de maisons ont
été endommagées, dont cinquante ont été détruites sur l’île principale de
Tonga, Tongatapu. La police locale, citée par les autorités néo-zélandaises,
a également fait état de deux morts, dont une Britannique âgée de 50 ans,
Angela Glover, emportée par le tsunami après avoir essayé de sauver les chiens
de son refuge, selon sa famille.`}).then(function (response) {
console.log(response.data);
})
.catch(function (err) {
console.error(err.response.status);
console.error(err.response.data.detail);
});
require 'vendor/autoload.php';
use NLPCloud\NLPCloud;
$client = new \NLPCloud\NLPCloud('bart-large-cnn','<token>', False, 'fr');
# Returns a json object.
echo json_encode($client->summarization("Sur des images aériennes, prises la veille par un vol de surveillance
de la Nouvelle-Zélande, la côte d’une île est bordée d’arbres passés du vert
au gris sous l’effet des retombées volcaniques. On y voit aussi des immeubles
endommagés côtoyer des bâtiments intacts. « D’après le peu d’informations
dont nous disposons, l’échelle de la dévastation pourrait être immense,
spécialement pour les îles les plus isolées », avait déclaré plus tôt
Katie Greenwood, de la Fédération internationale des sociétés de la Croix-Rouge.
Selon l’Organisation mondiale de la santé (OMS), une centaine de maisons ont
été endommagées, dont cinquante ont été détruites sur l’île principale de
Tonga, Tongatapu. La police locale, citée par les autorités néo-zélandaises,
a également fait état de deux morts, dont une Britannique âgée de 50 ans,
Angela Glover, emportée par le tsunami après avoir essayé de sauver les chiens
de son refuge, selon sa famille."));
Output:
{"summary_text": "Selon l'organisation mondiale de la santé, une centaine
de maisons ont été endommagées, dont 50 détruites sur l'île principale
de Tonga, Tongatapu. La police locale, citée par les autorités néo-zélandaises,
a également fait état de deux morts, dont une femme britannique de 50 ans,
Angela Glover. Glover a été emportée par le tsunami après avoir tenté
de sauver des chiens de son refuge."}
Example: performing French summarization with Bart Large CNN on GPU:
curl "https://api.nlpcloud.io/v1/gpu/fra_Latn/bart-large-cnn/summarization" \
-H "Authorization: Token <token>" \
-H "Content-Type: application/json" \
-X POST -d '{
"text":"Sur des images aériennes, prises la veille par un vol de surveillance
de la Nouvelle-Zélande, la côte d’une île est bordée d’arbres passés du vert
au gris sous l’effet des retombées volcaniques. On y voit aussi des immeubles
endommagés côtoyer des bâtiments intacts. « D’après le peu d’informations
dont nous disposons, l’échelle de la dévastation pourrait être immense,
spécialement pour les îles les plus isolées », avait déclaré plus tôt
Katie Greenwood, de la Fédération internationale des sociétés de la Croix-Rouge.
Selon l’Organisation mondiale de la santé (OMS), une centaine de maisons ont
été endommagées, dont cinquante ont été détruites sur l’île principale de
Tonga, Tongatapu. La police locale, citée par les autorités néo-zélandaises,
a également fait état de deux morts, dont une Britannique âgée de 50 ans,
Angela Glover, emportée par le tsunami après avoir essayé de sauver les chiens
de son refuge, selon sa famille."
}'
import nlpcloud
client = nlpcloud.Client("<model_name>", "<token>", gpu=True, lang="fra_Latn")
# Returns a json object.
client.summarization("""Sur des images aériennes, prises la veille par un vol de surveillance
de la Nouvelle-Zélande, la côte d’une île est bordée d’arbres passés du vert
au gris sous l’effet des retombées volcaniques. On y voit aussi des immeubles
endommagés côtoyer des bâtiments intacts. « D’après le peu d’informations
dont nous disposons, l’échelle de la dévastation pourrait être immense,
spécialement pour les îles les plus isolées », avait déclaré plus tôt
Katie Greenwood, de la Fédération internationale des sociétés de la Croix-Rouge.
Selon l’Organisation mondiale de la santé (OMS), une centaine de maisons ont
été endommagées, dont cinquante ont été détruites sur l’île principale de
Tonga, Tongatapu. La police locale, citée par les autorités néo-zélandaises,
a également fait état de deux morts, dont une Britannique âgée de 50 ans,
Angela Glover, emportée par le tsunami après avoir essayé de sauver les chiens
de son refuge, selon sa famille.""")
require 'nlpcloud'
client = NLPCloud::Client.new('<model_name>','<token>', gpu: true, lang: 'fr')
# Returns a json object.
client.summarization("Sur des images aériennes, prises la veille par un vol de surveillance
de la Nouvelle-Zélande, la côte d’une île est bordée d’arbres passés du vert
au gris sous l’effet des retombées volcaniques. On y voit aussi des immeubles
endommagés côtoyer des bâtiments intacts. « D’après le peu d’informations
dont nous disposons, l’échelle de la dévastation pourrait être immense,
spécialement pour les îles les plus isolées », avait déclaré plus tôt
Katie Greenwood, de la Fédération internationale des sociétés de la Croix-Rouge.
Selon l’Organisation mondiale de la santé (OMS), une centaine de maisons ont
été endommagées, dont cinquante ont été détruites sur l’île principale de
Tonga, Tongatapu. La police locale, citée par les autorités néo-zélandaises,
a également fait état de deux morts, dont une Britannique âgée de 50 ans,
Angela Glover, emportée par le tsunami après avoir essayé de sauver les chiens
de son refuge, selon sa famille.")
import (
"net/http"
"github.com/nlpcloud/nlpcloud-go"
)
func main() {
client := nlpcloud.NewClient(&http.Client{}, nlpcloud.ClientParams{Model:"<model_name>", Token:"<token>",
GPU:true, Lang:"fra_Latn", Async:false})
// Returns a Summarization struct.
summary, err := client.Summarization(nlpcloud.SummarizationParams{
Text: `Sur des images aériennes, prises la veille par un vol de surveillance
de la Nouvelle-Zélande, la côte d’une île est bordée d’arbres passés du vert
au gris sous l’effet des retombées volcaniques. On y voit aussi des immeubles
endommagés côtoyer des bâtiments intacts. « D’après le peu d’informations
dont nous disposons, l’échelle de la dévastation pourrait être immense,
spécialement pour les îles les plus isolées », avait déclaré plus tôt
Katie Greenwood, de la Fédération internationale des sociétés de la Croix-Rouge.
Selon l’Organisation mondiale de la santé (OMS), une centaine de maisons ont
été endommagées, dont cinquante ont été détruites sur l’île principale de
Tonga, Tongatapu. La police locale, citée par les autorités néo-zélandaises,
a également fait état de deux morts, dont une Britannique âgée de 50 ans,
Angela Glover, emportée par le tsunami après avoir essayé de sauver les chiens
de son refuge, selon sa famille.`,
})
...
}
const NLPCloudClient = require('nlpcloud');
const client = new NLPCloudClient({model:'<model_name>', token:'<token>', gpu:true, lang:'fra_Latn'})
// Returns an Axios promise with the results.
// In case of success, results are contained in `response.data`.
// In case of failure, you can retrieve the status code in `err.response.status`
// and the error message in `err.response.data.detail`.
client.summarization({text:`Sur des images aériennes, prises la veille par un vol de surveillance
de la Nouvelle-Zélande, la côte d’une île est bordée d’arbres passés du vert
au gris sous l’effet des retombées volcaniques. On y voit aussi des immeubles
endommagés côtoyer des bâtiments intacts. « D’après le peu d’informations
dont nous disposons, l’échelle de la dévastation pourrait être immense,
spécialement pour les îles les plus isolées », avait déclaré plus tôt
Katie Greenwood, de la Fédération internationale des sociétés de la Croix-Rouge.
Selon l’Organisation mondiale de la santé (OMS), une centaine de maisons ont
été endommagées, dont cinquante ont été détruites sur l’île principale de
Tonga, Tongatapu. La police locale, citée par les autorités néo-zélandaises,
a également fait état de deux morts, dont une Britannique âgée de 50 ans,
Angela Glover, emportée par le tsunami après avoir essayé de sauver les chiens
de son refuge, selon sa famille.`}).then(function (response) {
console.log(response.data);
})
.catch(function (err) {
console.error(err.response.status);
console.error(err.response.data.detail);
});
require 'vendor/autoload.php';
use NLPCloud\NLPCloud;
$client = new \NLPCloud\NLPCloud('<model_name>','<token>', True, 'fr');
# Returns a json object.
echo json_encode($client->summarization("Sur des images aériennes, prises la veille par un vol de surveillance
de la Nouvelle-Zélande, la côte d’une île est bordée d’arbres passés du vert
au gris sous l’effet des retombées volcaniques. On y voit aussi des immeubles
endommagés côtoyer des bâtiments intacts. « D’après le peu d’informations
dont nous disposons, l’échelle de la dévastation pourrait être immense,
spécialement pour les îles les plus isolées », avait déclaré plus tôt
Katie Greenwood, de la Fédération internationale des sociétés de la Croix-Rouge.
Selon l’Organisation mondiale de la santé (OMS), une centaine de maisons ont
été endommagées, dont cinquante ont été détruites sur l’île principale de
Tonga, Tongatapu. La police locale, citée par les autorités néo-zélandaises,
a également fait état de deux morts, dont une Britannique âgée de 50 ans,
Angela Glover, emportée par le tsunami après avoir essayé de sauver les chiens
de son refuge, selon sa famille."));
Output:
{"summary_text": "Selon l'organisation mondiale de la santé, une centaine
de maisons ont été endommagées, dont 50 détruites sur l'île principale
de Tonga, Tongatapu. La police locale, citée par les autorités néo-zélandaises,
a également fait état de deux morts, dont une femme britannique de 50 ans,
Angela Glover. Glover a été emportée par le tsunami après avoir tenté
de sauver des chiens de son refuge."}
AI models do not always work well with non-English languages.
We do our best to add non-English models when it's possible. See for example Fine-tuned LLaMA 3 70B, XLM Roberta Large XNLI, Paraphrase Multilingual MPNet Base V2, or spaCy. Unfortunately not all the models are good at handling non-English languages.
In order to solve this challenge, we developed a multilingual module that automatically translates your input into English, performs the actual natural language processing task, and then translates the result back to your original language. It makes your requests a bit slower but returns good results in many languages.
Even for models that natively understand non-English languages, they actually sometimes work better with the multilingual addon.
This multilingual add-on is free of charge and automatically used when you add a language code in your URL.
Simply add your language code in the endpoint URL, after the API version and before the name of the model: https://api.nlpcloud.io/v1/{language code}/{model}
If you are using a GPU, add your language code after the GPU, and before the name of the model: https://api.nlpcloud.io/v1/gpu/{language code}/{model}
For example, here is the endpoint you should use for summarization of French text with Bart Large CNN: https://api.nlpcloud.io/v1/fra_Latn/bart-large-cnn/summarization. And here is the endpoint you should use for summarization of French text with Bart Large CNN on GPU: https://api.nlpcloud.io/v1/fra_Latn/bart-large-cnn/summarization.
Here is the full list of supported language codes:
| Language | Code |
|---|---|
| Acehnese (Arabic script) | ace_Arab |
| Acehnese (Latin script) | ace_Latn |
| Mesopotamian Arabic | acm_Arab |
| Ta’izzi-Adeni Arabic | acq_Arab |
| Tunisian Arabic | aeb_Arab |
| Afrikaans | afr_Latn |
| South Levantine Arabic | ajp_Arab |
| Akan | aka_Latn |
| Amharic | amh_Ethi |
| North Levantine Arabic | apc_Arab |
| Modern Standard Arabic | arb_Arab |
| Modern Standard Arabic (Romanized) | arb_Latn |
| Najdi Arabic | ars_Arab |
| Moroccan Arabic | ary_Arab |
| Egyptian Arabic | arz_Arab |
| Assamese | asm_Beng |
| Asturian | ast_Latn |
| Awadhi | awa_Deva |
| Central Aymara | ayr_Latn |
| South Azerbaijani | azb_Arab |
| North Azerbaijani | azj_Latn |
| Bashkir | bak_Cyrl |
| Bambara | bam_Latn |
| Balinese | ban_Latn |
| Belarusian | bel_Cyrl |
| Bemba | bem_Latn |
| Bengali | ben_Beng |
| Bhojpuri | bho_Deva |
| Banjar (Arabic script) | bjn_Arab |
| Banjar (Latin script) | bjn_Latn |
| Standard Tibetan | bod_Tibt |
| Bosnian | bos_Latn |
| Buginese | bug_Latn |
| Bulgarian | bul_Cyrl |
| Catalan | cat_Latn |
| Cebuano | ceb_Latn |
| Czech | ces_Latn |
| Chokwe | cjk_Latn |
| Central Kurdish | ckb_Arab |
| Crimean Tatar | crh_Latn |
| Welsh | cym_Latn |
| Danish | dan_Latn |
| German | deu_Latn |
| Southwestern Dinka | dik_Latn |
| Dyula | dyu_Latn |
| Dzongkha | dzo_Tibt |
| Greek | ell_Grek |
| Esperanto | epo_Latn |
| Estonian | est_Latn |
| Basque | eus_Latn |
| Ewe | ewe_Latn |
| Faroese | fao_Latn |
| Fijian | fij_Latn |
| Finnish | fin_Latn |
| Fon | fon_Latn |
| French | fra_Latn |
| Friulian | fur_Latn |
| Nigerian Fulfulde | fuv_Latn |
| Scottish Gaelic | gla_Latn |
| Irish | gle_Latn |
| Galician | glg_Latn |
| Guarani | grn_Latn |
| Gujarati | guj_Gujr |
| Haitian Creole | hat_Latn |
| Hausa | hau_Latn |
| Hebrew | heb_Hebr |
| Hindi | hin_Deva |
| Chhattisgarhi | hne_Deva |
| Croatian | hrv_Latn |
| Hungarian | hun_Latn |
| Armenian | hye_Armn |
| Igbo | ibo_Latn |
| Ilocano | ilo_Latn |
| Indonesian | ind_Latn |
| Icelandic | isl_Latn |
| Italian | ita_Latn |
| Javanese | jav_Latn |
| Japanese | jpn_Jpan |
| Kabyle | kab_Latn |
| Jingpho | kac_Latn |
| Kamba | kam_Latn |
| Kannada | kan_Knda |
| Kashmiri (Arabic script) | kas_Arab |
| Kashmiri (Devanagari script) | kas_Deva |
| Georgian | kat_Geor |
| Central Kanuri (Arabic script) | knc_Arab |
| Central Kanuri (Latin script) | knc_Latn |
| Kazakh | kaz_Cyrl |
| Kabiyè | kbp_Latn |
| Kabuverdianu | kea_Latn |
| Khmer | khm_Khmr |
| Kikuyu | kik_Latn |
| Kinyarwanda | kin_Latn |
| Kyrgyz | kir_Cyrl |
| Kimbundu | kmb_Latn |
| Northern Kurdish | kmr_Latn |
| Kikongo | kon_Latn |
| Korean | kor_Hang |
| Lao | lao_Laoo |
| Ligurian | lij_Latn |
| Limburgish | lim_Latn |
| Lingala | lin_Latn |
| Lithuanian | lit_Latn |
| Lombard | lmo_Latn |
| Latgalian | ltg_Latn |
| Luxembourgish | ltz_Latn |
| Luba-Kasai | lua_Latn |
| Ganda | lug_Latn |
| Luo | luo_Latn |
| Mizo | lus_Latn |
| Standard Latvian | lvs_Latn |
| Magahi | mag_Deva |
| Maithili | mai_Deva |
| Malayalam | mal_Mlym |
| Marathi | mar_Deva |
| Minangkabau (Arabic script) | min_Arab |
| Minangkabau (Latin script) | min_Latn |
| Macedonian | mkd_Cyrl |
| Plateau Malagasy | plt_Latn |
| Maltese | mlt_Latn |
| Meitei (Bengali script) | mni_Beng |
| Halh Mongolian | khk_Cyrl |
| Mossi | mos_Latn |
| Maori | mri_Latn |
| Burmese | mya_Mymr |
| Dutch | nld_Latn |
| Norwegian Nynorsk | nno_Latn |
| Norwegian Bokmål | nob_Latn |
| Nepali | npi_Deva |
| Northern Sotho | nso_Latn |
| Nuer | nus_Latn |
| Nyanja | nya_Latn |
| Occitan | oci_Latn |
| West Central Oromo | gaz_Latn |
| Odia | ory_Orya |
| Pangasinan | pag_Latn |
| Eastern Panjabi | pan_Guru |
| Papiamento | pap_Latn |
| Western Persian | pes_Arab |
| Polish | pol_Latn |
| Portuguese | por_Latn |
| Dari | prs_Arab |
| Southern Pashto | pbt_Arab |
| Ayacucho Quechua | quy_Latn |
| Romanian | ron_Latn |
| Rundi | run_Latn |
| Russian | rus_Cyrl |
| Sango | sag_Latn |
| Sanskrit | san_Deva |
| Santali | sat_Olck |
| Sicilian | scn_Latn |
| Shan | shn_Mymr |
| Sinhala | sin_Sinh |
| Slovak | slk_Latn |
| Slovenian | slv_Latn |
| Samoan | smo_Latn |
| Shona | sna_Latn |
| Sindhi | snd_Arab |
| Somali | som_Latn |
| Southern Sotho | sot_Latn |
| Spanish | spa_Latn |
| Tosk Albanian | als_Latn |
| Sardinian | srd_Latn |
| Serbian | srp_Cyrl |
| Swati | ssw_Latn |
| Sundanese | sun_Latn |
| Swedish | swe_Latn |
| Swahili | swh_Latn |
| Silesian | szl_Latn |
| Tamil | tam_Taml |
| Tatar | tat_Cyrl |
| Telugu | tel_Telu |
| Tajik | tgk_Cyrl |
| Tagalog | tgl_Latn |
| Thai | tha_Thai |
| Tigrinya | tir_Ethi |
| Tamasheq (Latin script) | taq_Latn |
| Tamasheq (Tifinagh script) | taq_Tfng |
| Tok Pisin | tpi_Latn |
| Tswana | tsn_Latn |
| Tsonga | tso_Latn |
| Turkmen | tuk_Latn |
| Tumbuka | tum_Latn |
| Turkish | tur_Latn |
| Twi | twi_Latn |
| Central Atlas Tamazight | tzm_Tfng |
| Uyghur | uig_Arab |
| Ukrainian | ukr_Cyrl |
| Umbundu | umb_Latn |
| Urdu | urd_Arab |
| Northern Uzbek | uzn_Latn |
| Venetian | vec_Latn |
| Vietnamese | vie_Latn |
| Waray | war_Latn |
| Wolof | wol_Latn |
| Xhosa | xho_Latn |
| Eastern Yiddish | ydd_Hebr |
| Yoruba | yor_Latn |
| Yue Chinese | yue_Hant |
| Chinese (Simplified) | zho_Hans |
| Chinese (Traditional) | zho_Hant |
| Standard Malay | zsm_Latn |
| Zulu | zul_Latn |
The multilingual add-on can be used with the following endpoints:
- chatbot (chatbot and conversational AI)
- classification (text classification)
- generation (text generation)
- gs-correction (grammar and spelling correction)
- intent-classification (intent classification)
- image-generation (image generation)
- kw-kp-extraction (keywords and keyphrases extraction)
- paraphrasing (paraphrasing / rewriting)
- question (question answering)
- semantic-search (semantic search)
- sentiment-analysis (sentiment analysis / emotion analysis)
- summarization (text summarization)
Asynchronous Mode
Input (1st request):
curl "https://api.nlpcloud.io/v1/gpu/async/whisper/asr" \
-H "Authorization: Token <token>" \
-H "Content-Type: application/json" \
-X POST -d '{"url":"https://ia801405.us.archive.org/17/items/children_at_play_2210.poem_librivox/childrenatplay_davies_ah_64kb.mp3"}'
import nlpcloud
client = nlpcloud.Client("whisper", "<token>", gpu=True, asynchronous=True)
client.asr("https://ia801405.us.archive.org/17/items/children_at_play_2210.poem_librivox/childrenatplay_davies_ah_64kb.mp3")
require 'nlpcloud'
client = NLPCloud::Client.new('whisper','<token>', gpu: true, asynchronous: true)
client.asr(url:"https://ia801405.us.archive.org/17/items/children_at_play_2210.poem_librivox/childrenatplay_davies_ah_64kb.mp3")
import (
"net/http"
"github.com/nlpcloud/nlpcloud-go"
)
func main() {
client := nlpcloud.NewClient(&http.Client{}, nlpcloud.ClientParams{Model:"<model_name>", Token:"<token>",
GPU:true, Lang:"", Async:true})
asr, err := client.asr(nlpcloud.ASRParams{
URL: "https://ia801405.us.archive.org/17/items/children_at_play_2210.poem_librivox/childrenatplay_davies_ah_64kb.mp3",
})
...
}
const NLPCloudClient = require('nlpcloud');
const client = new NLPCloudClient({model:'whisper',token:'<token>',gpu:true,async:true})
// Returns an Axios promise with the results.
// In case of success, results are contained in `response.data`.
// In case of failure, you can retrieve the status code in `err.response.status`
// and the error message in `err.response.data.detail`.
client.asr({url:'https://ia801405.us.archive.org/17/items/children_at_play_2210.poem_librivox/childrenatplay_davies_ah_64kb.mp3'}).then(function (response) {
console.log(response.data);
})
.catch(function (err) {
console.error(err.response.status);
console.error(err.response.data.detail);
});
require 'vendor/autoload.php';
use NLPCloud\NLPCloud;
$client = new \NLPCloud\NLPCloud('whisper','<token>',True,'',True);
echo json_encode($client->asr("https://ia801405.us.archive.org/17/items/children_at_play_2210.poem_librivox/childrenatplay_davies_ah_64kb.mp3"));
Output (returns a 202 HTTP code):
{"url":"https://api.nlpcloud.io/v1/get-async-result/86cfbf00-f442-40b1-bb89-275d7d32fd48"}
Some AI models can take a long time to return. It is impractical to use these models through an API in a synchronous way. The solution is to ask for an asynchronous response. In that case your request will be processed in the background, and you will have to poll the result on a regular basis until it is ready.
When used in asynchronous mode, our AI models accept much larger inputs.
In order to use this mode, you should add /async/ to the url after the GPU (if you use a GPU) and before the language (if you use the multilingual addon). Here are some examples:
- If you use a GPU but not the multilingual addon:
https://api.nlpcloud.io/v1/gpu/async/{model} - If you use a GPU and the French language with the multilingual addon:
https://api.nlpcloud.io/v1/gpu/async/fra_Latn/{model} - If you don't use a GPU and don'use the multilingual addon:
https://api.nlpcloud.io/v1/async/{model} - If you don't use a GPU and use the French language with the multilingual addon:
https://api.nlpcloud.io/v1/async/fr_Latn/{model}
It instantly returns a URL (with HTTP code 202) containing a unique ID that you should use to retrieve your result once it is ready. You should poll this URL on a regular basis until the result is ready. If the result is not ready, an HTTP code 202 will be returned. If it is ready, an HTTP code 200 will be returned. It is good practice to poll the result URL every 10 seconds.
Input (2nd request):
curl "https://api.nlpcloud.io/v1/get-async-result/<your unique ID>" \
-H "Authorization: Token <token>"
# Returns a json object.
client.async_result("https://api.nlpcloud.io/v1/get-async-result/<your unique ID>")
client.async_result("https://api.nlpcloud.io/v1/get-async-result/<your unique ID>")
asr, err := client.asr(nlpcloud.AsyncResultParams{
URL: "https://api.nlpcloud.io/v1/get-async-result/<your unique ID>",
})
client.asyncResult('https://api.nlpcloud.io/v1/get-async-result/<your unique ID>').then(function (response) {
console.log(response.data);
})
.catch(function (err) {
console.error(err.response.status);
console.error(err.response.data.detail);
});
echo json_encode($client->asyncResult("https://api.nlpcloud.io/v1/get-async-result/<your unique ID>"));
Output (returns a 202 HTTP code with an empty body if not ready, or a 200 HTTP code with the result if ready):
{
"created_on":"2022-11-18T15:56:16.536025Z",
"request_body":"{\"url\":\"https://ia801405.us.archive.org/17/items/children_at_play_2210.poem_librivox/childrenatplay_davies_ah_64kb.mp3\"}",
"finished_on":"2022-11-18T15:56:29.393898Z",
"http_code":200,
"error_detail":"",
"content":"{\"text\":\" CHILDREN AT PLAY by William Henry Davies Read for LibriVox.org by Anita Hibbard, September 27, 2022 I hear a merry noise indeed. Is it the geese and ducks that take their first plunge in a quiet pond, that into scores of ripples break? Or children make this merry sound. I see an oak tree, its strong back could not be bent an inch, though all its leaves were stone, or iron even. A boy, with many a lusty call, rides on a bough bareback through heaven. I see two children dig a hole, and plant in it a cherry stone. We'll come tomorrow, one child said, and then the tree will be full grown and all its boughs have cherries red. Ah, children, what a life to lead! You love the flowers, but when they're past, no flowers are missed by your bright eyes, and when cold winter comes at last, snowflakes shall be your butterflies.\",\"duration\":82,\"language\":\"en\",\"segments\":[{\"id\":0,\"start\":0.0,\"end\":8.94,\"text\":\" CHILDREN AT PLAY by William Henry Davies Read for LibriVox.org by Anita Hibbard, September\"},{\"id\":1,\"start\":8.94,\"end\":11.76,\"text\":\" 27, 2022\"},{\"id\":2,\"start\":11.76,\"end\":14.8,\"text\":\" I hear a merry noise indeed.\"},{\"id\":3,\"start\":14.8,\"end\":21.04,\"text\":\" Is it the geese and ducks that take their first plunge in a quiet pond, that into scores\"},{\"id\":4,\"start\":21.04,\"end\":22.96,\"text\":\" of ripples break?\"},{\"id\":5,\"start\":22.96,\"end\":26.04,\"text\":\" Or children make this merry sound.\"},{\"id\":6,\"start\":26.04,\"end\":32.64,\"text\":\" I see an oak tree, its strong back could not be bent an inch, though all its leaves were\"},{\"id\":7,\"start\":32.64,\"end\":35.04,\"text\":\" stone, or iron even.\"},{\"id\":8,\"start\":35.04,\"end\":41.84,\"text\":\" A boy, with many a lusty call, rides on a bough bareback through heaven.\"},{\"id\":9,\"start\":41.84,\"end\":46.8,\"text\":\" I see two children dig a hole, and plant in it a cherry stone.\"},{\"id\":10,\"start\":46.8,\"end\":53.68,\"text\":\" We'll come tomorrow, one child said, and then the tree will be full grown and all its boughs\"},{\"id\":11,\"start\":53.68,\"end\":56.0,\"text\":\" have cherries red.\"},{\"id\":12,\"seek\":5600,\"start\":56.0,\"end\":59.76,\"text\":\" Ah, children, what a life to lead!\"},{\"id\":13,\"seek\":5600,\"start\":59.76,\"end\":66.24,\"text\":\" You love the flowers, but when they're past, no flowers are missed by your bright eyes,\"},{\"id\":14,\"seek\":6624,\"start\":66.24,\"end\":91.56,\"text\":\" and when cold winter comes at last, snowflakes shall be your butterflies.\"}]}"
}
The asynchronous mode can be used with the following endpoints:
- asr (automatic speech recognition): the maximum input audio/video length is 60,000 seconds in asynchronous mode, while it is 200 seconds in synchronous mode
- entities (entity extraction): the maximum input text is 1 million tokens in asynchronous mode, while in synchronous mode it is 256 tokens in synchronous mode. Under the hood, your input text is automatically split into several smaller requests, and then the result is reassembled after the fact.
- gs-correction (grammar and spelling correction): the maximum input text is 1 million tokens in asynchronous mode, while in synchronous mode it is 256 tokens in synchronous mode. Under the hood, your input text is automatically split into several smaller requests, and then the result is reassembled after the fact.
- kw-kp-extraction (keywords and keyphrases extraction): the maximum input text is 1 million tokens in asynchronous mode, while in synchronous mode it is 1024 tokens in synchronous mode. Under the hood, your input text is automatically split into several smaller requests, and then the result is reassembled after the fact.
- paraphrasing (paraphrasing and rewriting): the maximum input text is 1 million tokens in asynchronous mode, while it is 256 tokens in synchronous mode. Under the hood, your input text is automatically split into several smaller requests, and then the result is reassembled after the fact.
- summarization (text summarization): the maximum input text is 1 million tokens in asynchronous mode, while in synchronous mode it is 1024 tokens for Bart Large and GPT, and 8192 tokens for T5 Base Headline Generation. Under the hood, your input text is automatically split into several smaller requests, and then the result is reassembled after the fact.
- translation (translation): the maximum input text is 1 million tokens in asynchronous mode, while it is 256 tokens in synchronous mode. Under the hood, your input text is automatically split into several smaller requests, and then the result is reassembled after the fact.
First HTTP Request
POST https://api.nlpcloud.io/v1/<gpu if any>/<language if any>/async/<model>/<endpoint>
POST Values
Should contain the same values as the underlying endpoint you are trying to use.
Output
This endpoint returns a JSON object containing the following elements:
| Key | Type | Description |
|---|---|---|
url |
string | The url that you should poll to get the final result |
Second HTTP Request
GET https://api.nlpcloud.io/v1/get-async-result/<your unique ID>
Output
This endpoint returns a JSON object containing the following elements:
| Key | Type | Description |
|---|---|---|
created_on |
datetime | The date and time of your initial request |
request_body |
string | The content of your initial request |
finished_on |
datetime | The date and time when your request was completed |
http_code |
int | The HTTP code returned by the AI model |
error_detail |
string | The error returned by the AI model if any |
content |
string | The response returned by the AI model |
Endpoints
Automatic Speech Recognition
Input:
curl "https://api.nlpcloud.io/v1/gpu/whisper/asr" \
-H "Authorization: Token <token>" \
-H "Content-Type: application/json" \
-X POST -d '{"url":"https://ia801405.us.archive.org/17/items/children_at_play_2210.poem_librivox/childrenatplay_davies_ah_64kb.mp3"}'
import nlpcloud
client = nlpcloud.Client("whisper", "<token>", True)
# Returns a json object.
client.asr("https://ia801405.us.archive.org/17/items/children_at_play_2210.poem_librivox/childrenatplay_davies_ah_64kb.mp3")
require 'nlpcloud'
client = NLPCloud::Client.new('whisper','<token>', gpu: true)
# Returns a json object.
client.asr(url:"https://ia801405.us.archive.org/17/items/children_at_play_2210.poem_librivox/childrenatplay_davies_ah_64kb.mp3")
import (
"net/http"
"github.com/nlpcloud/nlpcloud-go"
)
func main() {
client := nlpcloud.NewClient(&http.Client{}, nlpcloud.ClientParams{Model:"<model_name>", Token:"<token>",
GPU:true, Lang:"", Async:false})
// Returns an ASR struct.
asr, err := client.asr(nlpcloud.ASRParams{
URL: "https://ia801405.us.archive.org/17/items/children_at_play_2210.poem_librivox/childrenatplay_davies_ah_64kb.mp3",
})
...
}
const NLPCloudClient = require('nlpcloud');
const client = new NLPCloudClient({model:'whisper',token:'<token>',gpu:true})
// Returns an Axios promise with the results.
// In case of success, results are contained in `response.data`.
// In case of failure, you can retrieve the status code in `err.response.status`
// and the error message in `err.response.data.detail`.
client.asr({url:'https://ia801405.us.archive.org/17/items/children_at_play_2210.poem_librivox/childrenatplay_davies_ah_64kb.mp3'}).then(function (response) {
console.log(response.data);
})
.catch(function (err) {
console.error(err.response.status);
console.error(err.response.data.detail);
});
require 'vendor/autoload.php';
use NLPCloud\NLPCloud;
$client = new \NLPCloud\NLPCloud('whisper','<token>',True);
# Returns a json object.
echo json_encode($client->asr("https://ia801405.us.archive.org/17/items/children_at_play_2210.poem_librivox/childrenatplay_davies_ah_64kb.mp3"));
Output:
{
"text": " CHILDREN AT PLAY by William Henry Davies Read for LibriVox.org by Anita Hibbard, September 27, 2022 I hear a merry noise indeed. Is it the geese and ducks that take their first plunge in a quiet pond, that into scores of ripples break? Or children make this merry sound. I see an oak tree, its strong back could not be bent an inch, though all its leaves were stone, or iron even. A boy, with many a lusty call, rides on a bough bareback through heaven. I see two children dig a hole, and plant in it a cherry stone. We'll come tomorrow, one child said, and then the tree will be full grown and all its boughs have cherries red. Ah, children, what a life to lead! You love the flowers, but when they're past, no flowers are missed by your bright eyes, and when cold winter comes at last, snowflakes shall be your butterflies.",
"duration": 82,
"language": "en",
"segments": [
{
"id": 0,
"start": 0,
"end": 8.94,
"text": " CHILDREN AT PLAY by William Henry Davies Read for LibriVox.org by Anita Hibbard, September"
},
{
"id": 1,
"start": 8.94,
"end": 11.76,
"text": " 27, 2022"
},
[...]
{
"id": 13,
"start": 59.76,
"end": 66.24,
"text": " You love the flowers, but when they're past, no flowers are missed by your bright eyes,"
},
{
"id": 14,
"start": 66.24,
"end": 82,
"text": " and when cold winter comes at last, snowflakes shall be your butterflies."
}
],
"words": [
{
"id": 0,
"text": " Children",
"start": 0.75,
"end": 1.37
},
{
"id": 1,
"text": " at",
"start": 1.37,
"end": 1.65
},
[...]
{
"id": 165,
"text": " public",
"start": 75.77,
"end": 76.03
},
{
"id": 166,
"text": " domain.",
"start": 76.03,
"end": 76.43
}]
}
This endpoint uses the OpenAI Whisper Large speech-to-text model to perform automatic speech recognition in 97 languages on an audio or a video file.
Pass a URL where your audio or video file is stored (on an AWS S3 bucket for example), or send a base 64 encoded version of your file within your request (here is an example showing how you can encode your file using Python). Then we will automatically retrieve the file and extract the text it contains. The input language is automatically detected by default, but if you know the input language it is best to pass the information to the model for better results. Punctuation is automatically added to the result. Timestamps are also automatically extracted (including word-level timestamps).
Here is the model you can use:
- whisper for automatic speech recognition in 97 languages. This model supports the following languages: english, chinese, german, spanish, russian, korean, french, japanese, portuguese, turkish, polish, catalan, dutch, arabic, swedish, italian, indonesian, hindi, finnish, vietnamese, hebrew, ukrainian, greek, malay, czech, romanian, danish, hungarian, tamil, norwegian, thai, urdu, croatian, bulgarian, lithuanian, latin, maori, malayalam, welsh, slovak, telugu, persian, latvian, bengali, serbian, azerbaijani, slovenian, kannada, estonian, macedonian, breton, basque, icelandic, armenian, nepali, mongolian, bosnian, kazakh, albanian, swahili, galician, marathi, punjabi, sinhala, khmer, shona, yoruba, somali, afrikaans, occitan, georgian, belarusian, tajik, sindhi, gujarati, amharic, yiddish, lao, uzbek, faroese, haitian creole, pashto, turkmen, nynorsk, maltese, sanskrit, luxembourgish, myanmar, tibetan, tagalog, malagasy, assamese, tatar, hawaiian, lingala, hausa, bashkir, javanese, and sundanese.
HTTP Request
POST https://api.nlpcloud.io/v1/gpu/whisper/asr
POST Values
These values must be encoded as JSON.
| Key | Type | Description |
|---|---|---|
url |
string | The url of your audio or video file. In synchronous mode, the file size should be 100MB maximum and duration should be 200 seconds maximum. In asynchronous mode, the file size should be 600MB maximum and the duration should be 60,000 seconds maximum. Input language is automatically detected. Either url or encoded_file should be set. |
encoded_file |
string | A base 64 encoded version of your audio or video file. Here is an example showing how you can encode your file using Python. In synchronous mode, the file size should be 100MB maximum and duration should be 200 seconds maximum. In asynchronous mode, the file size should be 600MB maximum and the duration should be 60,000 seconds maximum. Input language is automatically detected. Either url or encoded_file should be set. |
input_language |
string | Language of your file as ISO code (en: english, zh: chinese, de: german, es: spanish, ru: russian, ko: korean, fr: french, ja: japanese, pt: portuguese, tr: turkish, pl: polish, ca: catalan, nl: dutch, ar: arabic, sv: swedish, it: italian, id: indonesian, hi: hindi, fi: finnish, vi: vietnamese, he: hebrew, uk: ukrainian, el: greek, ms: malay, cs: czech, ro: romanian, da: danish, hu: hungarian, ta: tamil, no: norwegian, th: thai, ur: urdu, hr: croatian, bg: bulgarian, lt: lithuanian, la: latin, mi: maori, ml: malayalam, cy: welsh, sk: slovak, te: telugu, fa: persian, lv: latvian, bn: bengali, sr: serbian, az: azerbaijani, sl: slovenian, kn: kannada, et: estonian, mk: macedonian, br: breton, eu: basque, is: icelandic, hy: armenian, ne: nepali, mn: mongolian, bs: bosnian, kk: kazakh, sq: albanian, sw: swahili, gl: galician, mr: marathi, pa: punjabi, si: sinhala, km: khmer, sn: shona, yo: yoruba, so: somali, af: afrikaans, oc: occitan, ka: georgian, be: belarusian, tg: tajik, sd: sindhi, gu: gujarati, am: amharic, yi: yiddish, lo: lao, uz: uzbek, fo: faroese, ht: haitian creole, ps: pashto, tk: turkmen, nn: nynorsk, mt: maltese, sa: sanskrit, lb: luxembourgish, my: myanmar, bo: tibetan, tl: tagalog, mg: malagasy, as: assamese, tt: tatar, haw: hawaiian, ln: lingala, ha: hausa, ba: bashkir, jw: javanese, su: sundanese). If no input language is passed, the model will try to guess the language automatically. Optional. |
Output
This endpoint returns a JSON object containing the following elements:
| Key | Type | Description |
|---|---|---|
text |
string | The extracted text, with punctuation |
duration |
int | The duration of the input file, in seconds |
language |
string | Language (ISO code) of the input file, automatically detected |
segments |
array of objects | A list of all the timestamped segments extracted from the file (see more details below) |
words |
array of objects | A list of all the timestamped words extracted from the file (see more details below) |
Each extracted segment or word is made of the following:
| Key | Type | Description |
|---|---|---|
id |
int | The position of the segment in the list of segments |
start |
float | The starting position of the segment in the file, in seconds |
end |
float | The ending position of the segment in the file, in seconds |
text |
string | The text content of the segment |
Chatbot and Conversational AI
Input:
curl "https://api.nlpcloud.io/v1/gpu/<model>/chatbot" \
-H "Authorization: Token <token>" \
-H "Content-Type: application/json" \
-X POST -d '{
"input":"I just broke up with my girlfriend... What is your name by the way?",
"context":"This is a discussion between a human and an AI. The human is sad but the AI is empathetic and reassuring. The AI is called Patrick.",
"history":[{"input":"Hello friend", "response":"Hi there, how is it going today?" }, {"input":"Well, not that good...", "response":"Oh? What happened?"}]
}'
import nlpcloud
client = nlpcloud.Client("<model>", "<token>", True)
# Returns a json object.
client.chatbot("I just broke up with my girlfriend... What's your name by the way?",
context="This is a discussion between a human and an AI. The human is sad but the AI is empathetic and reassuring. The AI is called Patrick.",
history=[{"input":"Hello friend", "response":"Hi there, how is it going today?"}, {"input":"Well, not that good...", "response":"Oh? What happened?"}])
require 'nlpcloud'
client = NLPCloud::Client.new('<model>','<token>', gpu: true)
# Returns a json object.
client.chatbot("I just broke up with my girlfriend... What's your name by the way?",
context: "This is a discussion between a human and an AI. The human is sad but the AI is empathetic and reassuring. The AI is called Patrick.",
history: [{"input"=>"Hello friend", "response"=>"Hi there, how is it going today?"}, {"input"=>"Well, not that good...", "response"=>"Oh? What happened?"}])
import (
"net/http"
"github.com/nlpcloud/nlpcloud-go"
)
func main() {
client := nlpcloud.NewClient(&http.Client{}, nlpcloud.ClientParams{Model:"<model>", Token:"<token>",
GPU:true})
ptrContext = new(string)
*ptrContext = "This is a discussion between a human and an AI. The human is sad but the AI is empathetic and reassuring. The AI is called Patrick."
context := ptrContext
exchange1 := nlpcloud.Exchange{Input:"Hello friend", Response:"Hi there, how is it going today?"}
exchange2 := nlpcloud.Exchange{Input:"Well, not that good...", Response:"Oh? What happened?"}
// Returns a Chatbot struct.
chatbot, err := client.Chatbot(nlpcloud.ChatbotParams{
Input: "I just broke up with my girlfriend... What's your name by the way?",
Context: context,
History: *[]nlpcloud.Exchange{exchange1, exchange2}
})
...
}
const NLPCloudClient = require('nlpcloud');
const client = new NLPCloudClient({model:'<model>',token:'<token>',gpu:true})
// Returns an Axios promise with the results.
// In case of success, results are contained in `response.data`.
// In case of failure, you can retrieve the status code in `err.response.status`
// and the error message in `err.response.data.detail`.
client.chatbot({input:`I just broke up with my girlfriend... What's your name by the way?`, context:'This is a discussion between a human and an AI. The human is sad but the AI is empathetic and reassuring. The AI is called Patrick.', history:[{input:'Hello friend', response:'Hi there, how is it going today?'}, {input:'Well, not that good...', response:'Oh? What happened?'}]).then(function (response) {
console.log(response.data);
})
.catch(function (err) {
console.error(err.response.status);
console.error(err.response.data.detail);
});
require 'vendor/autoload.php';
use NLPCloud\NLPCloud;
$client = new \NLPCloud\NLPCloud('<model>','<token>', True);
# Returns a json object.
echo json_encode($client.chatbot("I just broke up with my girlfriend... What's your name by the way?", "This is a discussion between a human and an AI. The human is sad but the AI is empathetic and reassuring. The AI is called Patrick.", array(array("input"=>"Hello friend","response"=>"Hi there, how is it going today?"), array("input"=>"Well, not that good...","response"=>"Oh? What happened?"), ...)));
Output:
{
"response": "I'm really sorry to hear that... My name is Patrick.",
"history": [{"input":"Hello friend", "response":"Hi there, how is it going today?"}, {"input":"Well, not that good...", "response":"Oh? What happened?"}, {"input":"I just broke up with my girlfriend... What's your name by the way?", "response":"I'm really sorry to hear that... My name is Patrick."}]
}
This is an endpoint for conversational AI and chatbots. The model takes your input together with a context and a conversation history, and returns an answer based on that.
The context gives additional general details like the mood of the characters, facts about the persons involved, historical details, etc. In order for the context to work correctly, the model should be called "AI" and the user should be called "human". Here is an example: This is a discussion between a human and an AI. The human is sad but the AI is empathetic and reassuring. The AI is called Patrick..
Generative models don't have any memory, so you need to always send the conversation history together with your request so the model remembers what you talked about earlier. For more details, see our blog article about chatbots.
For conversational AI in non-English languages, you can use our multilingual add-on but note that Fine-tuned LLaMA 3 70B works well in many non English languages without even using the multilingual add-on.
If you want more control over your chatbot, you should use the text generation endpoint together with few shot learning. And for the best results, you should fine-tune your own model. You can also use your own custom model.
In order to create a chatbot that will correctly answer questions on your own knowledge, you will need to mix both semantic search and generative AI. Please read this article: Question Answering On Domain Knowledge With Semantic Search And Generative AI.
You can use the following models:
- finetuned-llama-3-70b: It natively understands the following languages: Albanian, Arabic, Armenian, Awadhi, Azerbaijani, Bashkir, Basque, Belarusian, Bengali, Bhojpuri, Bosnian, Brazilian Portuguese, Bulgarian, Cantonese (Yue), Catalan, Chhattisgarhi, Chinese, Croatian, Czech, Danish, Dogri, Dutch, English, Estonian, Faroese, Finnish, French, Galician, Georgian, German, Greek, Gujarati, Haryanvi, Hindi, Hungarian, Indonesian, Irish, Italian, Japanese, Javanese, Kannada, Kashmiri, Kazakh, Konkani, Korean, Kyrgyz, Latvian, Lithuanian, Macedonian, Maithili, Malay, Maltese, Mandarin, Mandarin Chinese, Marathi, Marwari, Min Nan, Moldovan, Mongolian, Montenegrin, Nepali, Norwegian, Oriya, Pashto, Persian (Farsi), Polish, Portuguese, Punjabi, Rajasthani, Romanian, Russian, Sanskrit, Santali, Serbian, Sindhi, Sinhala, Slovak, Slovene, Slovenian, Spanish, Swahili, Swedish, Tajik, Tamil, Tatar, Telugu, Thai, Turkish, Turkmen, Ukrainian, Urdu, Uzbek, Vietnamese, Welsh, and Wu.
- chatdolphin: It works best in English.
- dolphin-yi-34b: It works best in English.
- dolphin-mixtral-8x7b: It works best in English.
Input for streaming request:
curl -N --output - "https://api.nlpcloud.io/v1/gpu/<model>/chatbot" \
-H "Authorization: Token <token>" \
-H "Content-Type: application/json" \
-X POST -d '{
"input":"I just broke up with my girlfriend... What is your name by the way?",
"context":"This is a discussion between a human and an AI. The human is sad but the AI is empathetic and reassuring. The AI is called Patrick.",
"history":[{"input":"Hello friend", "response":"Hi there, how is it going today?" }, {"input":"Well, not that good...", "response":"Oh? What happened?"}],
"stream":true
}'
# Not implemented yet but here is how you can achieve it with
# the Requests library
import requests
url = "https://api.nlpcloud.io/v1/gpu/<model_name>/chatbot"
headers = {
"Authorization": "Token <token>",
"Content-Type": "application/json",
}
data = {
"input": "I just broke up with my girlfriend... What is your name by the way?",
"context": "This is a discussion between a human and an AI. The human is sad but the AI is empathetic and reassuring. The AI is called Patrick.",
"history": [
{"input": "Hello friend", "response": "Hi there, how is it going today?"},
{"input": "Well, not that good...", "response": "Oh? What happened?"},
],
"stream": True,
}
r = requests.post(url, headers=headers, json=data, stream=True)
for line in r.iter_lines():
if line:
decoded_line = line.decode('utf-8')
print(decoded_line)
# Not implemented yet
client := nlpcloud.NewClient(&http.Client{}, nlpcloud.ClientParams{Model: <model_name>, Token: <token>, GPU: true})
ptrContext = new(string)
*ptrContext = "This is a discussion between a human and an AI. The human is sad but the AI is empathetic and reassuring. The AI is called Patrick."
context := ptrContext
exchange1 := nlpcloud.Exchange{Input:"Hello friend", Response:"Hi there, how is it going today?"}
exchange2 := nlpcloud.Exchange{Input:"Well, not that good...", Response:"Oh? What happened?"}
streamBody, err := client.StreamingChatbot(nlpcloud.ChatbotParams{
Input: "I just broke up with my girlfriend... What's your name by the way?",
Context: context,
History: *[]nlpcloud.Exchange{exchange1, exchange2}
})
if err != nil {
log.Fatalln(err)
}
defer streamBody.Close()
stream := bufio.NewReader(streamBody)
for {
chunk, err := stream.ReadBytes('\x00')
if err != nil {
if errors.Is(err, io.EOF) {
break
}
log.Fatalln()
}
fmt.Println(string(chunk))
}
// Not implemented yet
// Not implemented yet
SSE output:
I'm really sorry to hear that... My name is Patrick.[DONE]
If you want the text to appear gradually as soon as it is generated (also known as "token streaming") you can use the stream parameter.
HTTP Request
POST https://api.nlpcloud.io/v1/gpu/<model_name>/chatbot
POST Values
These values must be encoded as JSON.
| Key | Type | Description |
|---|---|---|
input |
string | The thing you want to say to the chatbot. 4096 tokens maximum for Fine-tuned LLaMA 3 70B and 8192 for the other generative models. |
context |
string | A context for the conversation that gives potential details about the mood, facts, etc. Optional. 4096 tokens maximum for Fine-tuned LLaMA 3 70B and 8192 for the other generative models. |
history |
array of objects | The history of your previous exchanges with the chatbot. The order of the array is important: the last elements in the array should be the more recent discussions with the model. Each exchange is made of a an input (string) and a response (string). Optional. 4096 tokens maximum for Fine-tuned LLaMA 3 70B and 8192 for the other generative models. |
stream |
bool | Optional. Whether the response should be streamed. Defaults to false. |
Output
If stream is set to false, this endpoint returns a JSON object containing the following elements:
| Key | Type | Description |
|---|---|---|
response |
string | The response from the chatbot. |
history |
array of objects | The history of all your exchanges with the chatbot, including the current response. Each exchange is made of a an input (string) and a response (string) |
If stream is set to true, the endpoint returns the generated text as raw text through server sent events (SSE). Once the generation is finished, the endpoint returns "[DONE]". Note that in that case, history is not returned.
Classification
Input:
curl "https://api.nlpcloud.io/v1/<model_name>/classification" \
-H "Authorization: Token <token>" \
-H "Content-Type: application/json" \
-X POST \
-d '{
"text":"John Doe is a Go Developer at Google. He has been working there for 10 years and has been awarded employee of the year",
"labels":["job", "nature", "space"],
"multi_class": true
}'
import nlpcloud
client = nlpcloud.Client("<model_name>", "<token>")
# Returns a json object.
client.classification("""John Doe is a Go Developer at Google.
He has been working there for 10 years and has been
awarded employee of the year.""",
labels=["job", "nature", "space"],
multi_class=True)
require 'nlpcloud'
client = NLPCloud::Client.new('<model_name>','<token>')
# Returns a json object.
client.classification("John Doe is a Go Developer at Google.
He has been working there for 10 years and has been
awarded employee of the year.",
labels:["job", "nature", "space"],
multi_class: true)
import (
"net/http"
"github.com/nlpcloud/nlpcloud-go"
)
func newTrue() *bool {
b := true
return &b
}
func main() {
client := nlpcloud.NewClient(&http.Client{}, nlpcloud.ClientParams{Model:"<model_name>", Token:"<token>",
GPU:false, Lang:"", Async:false})
// Returns a Classification struct.
classes, err := client.Classification(nlpcloud.ClassificationParams{
Text: `John Doe is a Go Developer at Google. He has been working
there for 10 years and has been awarded employee of the year.`,
Labels: []string{"job", "nature", "space"},
MultiClass: newTrue(),
})
...
}
const NLPCloudClient = require('nlpcloud');
const client = new NLPCloudClient({model:'<model_name>',token:'<token>'})
// Returns an Axios promise with the results.
// In case of success, results are contained in `response.data`.
// In case of failure, you can retrieve the status code in `err.response.status`
// and the error message in `err.response.data.detail`.
client.classification({text:`John Doe is a Go Developer at Google.
He has been working there for 10 years and has been
awarded employee of the year.`,
labels:['job', 'nature', 'space'],
multiClass:true}).then(function (response) {
console.log(response.data);
})
.catch(function (err) {
console.error(err.response.status);
console.error(err.response.data.detail);
});
require 'vendor/autoload.php';
use NLPCloud\NLPCloud;
$client = new \NLPCloud\NLPCloud('<model_name>','<token>');
# Returns a json object.
echo json_encode($client->classification("John Doe is a Go Developer at Google.
He has been working there for 10 years and has been
awarded employee of the year.",
array("job", "nature", "space"),
True));
Output (using bart-large-mnli-yahoo-answers for the example):
{
"labels":["job", "space", "nature"],
"scores":[0.9258800745010376, 0.1938474327325821, 0.010988450609147549]
}
This endpoint performs classification on a piece of text, in many languages.
Bart Large MNLI Yahoo Answers and XLM Roberta Large XNLI force you to propose some candidate labels, and then the model picks the label that is the most likely to apply to your piece of text. Generative models like Fine-tuned LLaMA 3 70B: you can either propose a list of labels, or don't send any label at all. If you don't send any label, the model will try to categorize your piece of text from scratch. Generative models, give the best results but they are slower.
If you want more control over your GPT-based classification, you should use the text generation endpoint together with few shot learning. And for the best results, you should fine-tune your own model. You can also use your own custom model.
For classification in non-English languages, you can use our multilingual add-on. Note that Fine-tuned LLaMA 3 70B and XLM Roberta Large XNLI natively work quite well in many non English languages without even using the multilingual add-on.
Here are the models you can use:
- bart-large-mnli-yahoo-answers: Joe Davison's Bart Large MNLI Yahoo Answers is perfect for fast classification in English.
- xlm-roberta-large-xnli: Joe Davison's XLM Roberta Large XNLI is more suited if you need to perform fast classification in non-English languages. It works in more than 100 languages, and it is especially accurate in English, French, Spanish, German, Greek, Bulgarian, Russian, Turkish, Arabic, Vietnamese, Thai, Chinese, Hindi, Swahili, Urdu.
- finetuned-llama-3-70b: Fine-tuned LLaMA 3 70B works better than Bart, and XLM Roberta, but it is slower and more expensive. It works very well if you don't have candidate labels. It natively understands the following languages: Albanian, Arabic, Armenian, Awadhi, Azerbaijani, Bashkir, Basque, Belarusian, Bengali, Bhojpuri, Bosnian, Brazilian Portuguese, Bulgarian, Cantonese (Yue), Catalan, Chhattisgarhi, Chinese, Croatian, Czech, Danish, Dogri, Dutch, English, Estonian, Faroese, Finnish, French, Galician, Georgian, German, Greek, Gujarati, Haryanvi, Hindi, Hungarian, Indonesian, Irish, Italian, Japanese, Javanese, Kannada, Kashmiri, Kazakh, Konkani, Korean, Kyrgyz, Latvian, Lithuanian, Macedonian, Maithili, Malay, Maltese, Mandarin, Mandarin Chinese, Marathi, Marwari, Min Nan, Moldovan, Mongolian, Montenegrin, Nepali, Norwegian, Oriya, Pashto, Persian (Farsi), Polish, Portuguese, Punjabi, Rajasthani, Romanian, Russian, Sanskrit, Santali, Serbian, Sindhi, Sinhala, Slovak, Slovene, Slovenian, Spanish, Swahili, Swedish, Tajik, Tamil, Tatar, Telugu, Thai, Turkish, Turkmen, Ukrainian, Urdu, Uzbek, Vietnamese, Welsh, and Wu.
Pass your text along with a list of labels. The model will return a score for each label. The higher the score, the more likely the text is related to this label. If you're using a generative model, no meaningful score will be returned.
Here is an example using Postman:
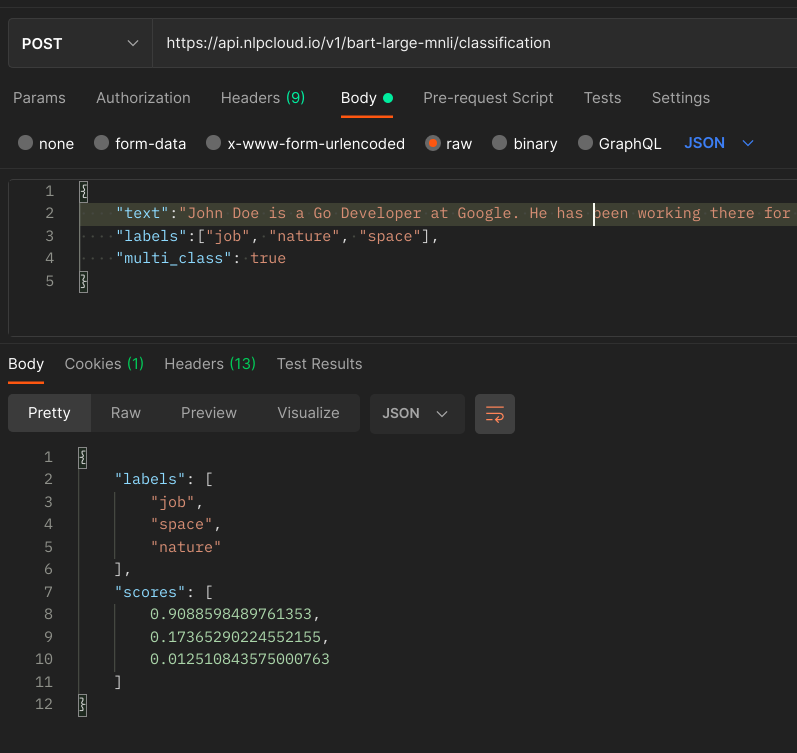
Put your JSON data in Body > raw. Note that if your text contains double quotes (") you will need to escape them (using \") in order for your JSON to be properly decoded. This is not needed when using a client library.
HTTP Request
POST https://api.nlpcloud.io/v1/<model_name>/classification
POST Values
These values must be encoded as JSON.
| Key | Type | Description |
|---|---|---|
text |
string | The block of text you want to analyze. 8192 tokens for Dolphin, Yi 34B, and Mixtral 8x7B. 2,500 tokens maximum for Bart Large MNLI Yahoo Answers and XLM Roberta Large XNLI. 4096 tokens for Fine-tuned LLaMA 3 70B. |
labels |
array | A list of labels you want to use to classify your text. 10 labels maximum (if you have more labels, you should make separate requests). Optional if you're using Dolphin, Yi 34B, Mixtral 8x7B, or Fine-tuned LLaMA 3 70B. |
multi_class |
boolean | Whether multiple labels should be applied to your text, meaning that the model will calculate an independent score for each label. Defaults to true. Only compatible with Bart Large MNLI Yahoo Answers and XLM Roberta Large XNLI. |
Output
This endpoint returns a JSON object containing a list of labels along with a list of scores. Order matters. For example, the second score in the list corresponds to the second label.
| Key | Type | Description |
|---|---|---|
labels |
array of strings | The labels you passed in your request |
scores |
array of floats | The scores applied to each label. Each score goes from 0 to 1. The higher the better. Not meaningful if you're using Dolphin, Yi 34B, Mixtral 8x7B, or Fine-tuned LLaMA 3 70B. |
Code Generation
Input:
curl "https://api.nlpcloud.io/v1/gpu/<model>/code-generation" \
-H "Authorization: Token <token>" \
-H "Content-Type: application/json" \
-X POST -d '{"instruction":"Generate a C++ program that sorts a list of integers in ascending order."}'
import nlpcloud
client = nlpcloud.Client("<model>", "<token>", True)
# Returns a json object.
client.code_generation("Generate a C++ program that sorts a list of integers in ascending order.")
require 'nlpcloud'
client = NLPCloud::Client.new('<model>','<token>', gpu: true)
# Returns a json object.
client.code_generation('Generate a C++ program that sorts a list of integers in ascending order.')
import (
"net/http"
"github.com/nlpcloud/nlpcloud-go"
)
func main() {
client := nlpcloud.NewClient(&http.Client{}, nlpcloud.ClientParams{Model:"<model_name>", Token:"<token>",
GPU:true, Lang:"", Async:false})
// Returns an ArticleGeneration struct.
codeGeneration, err := client.CodeGeneration(nlpcloud.CodeGenerationParams{
Text: "Generate a C++ program that sorts a list of integers in ascending order.",
})
...
}
const NLPCloudClient = require('nlpcloud');
const client = new NLPCloudClient({model:'<model>',token:'<token>',gpu:true})
// Returns an Axios promise with the results.
// In case of success, results are contained in `response.data`.
// In case of failure, you can retrieve the status code in `err.response.status`
// and the error message in `err.response.data.detail`.
client.codeGeneration({instruction:'Generate a C++ program that sorts a list of integers in ascending order.'}).then(function (response) {
console.log(response.data);
})
.catch(function (err) {
console.error(err.response.status);
console.error(err.response.data.detail);
});
require 'vendor/autoload.php';
use NLPCloud\NLPCloud;
$client = new \NLPCloud\NLPCloud('<model>','<token>', True);
# Returns a json object.
echo json_encode($client->codeGeneration("Generate a C++ program that sorts a list of integers in ascending order."));
Output:
{
"generated_code": "
#include <iostream>
using namespace std;
void swap(int* a, int* b)
{
int t = *a;
*a = *b;
*b = t;
}
int partition (int arr[], int low, int high)
{
int pivot = arr[high];
int i = (low - 1);
for (int j = low; j <= high- 1; j++)
{
if (arr[j] <= pivot)
{
i++;
swap(&arr[i], &arr[j]);
}
}
swap(&arr[i + 1], &arr[high]);
return (i + 1);
}
void quickSort(int arr[], int low, int high)
{
if (low < high)
{
int pi = partition(arr, low, high);
quickSort(arr, low, pi - 1);
quickSort(arr, pi + 1, high);
}
}
void printArray(int arr[], int size)
{
int i;
for (i=0; i < size; i++)
cout << arr[i] << " ";
cout << endl;
}
int main()
{
int arr[] = {10, 7, 8, 9, 1, 5};
int n = sizeof(arr)/sizeof(arr[0]);
quickSort(arr, 0, n-1);
cout << "Sorted array: \n";
printArray(arr, n);
return 0;
}"
}
This is an endpoint for source code generation. The endpoint takes a short instruction and generates a source code out of it in any programming language. Make sure to mention the language you want to use in your instruction.
If you want more control over this task, you should use the text generation endpoint together with few shot learning. And for the best results, you should fine-tune your own model. You can also use your own custom model.
The following models are available:
- finetuned-llama-3-70b: It natively understands the following languages: Albanian, Arabic, Armenian, Awadhi, Azerbaijani, Bashkir, Basque, Belarusian, Bengali, Bhojpuri, Bosnian, Brazilian Portuguese, Bulgarian, Cantonese (Yue), Catalan, Chhattisgarhi, Chinese, Croatian, Czech, Danish, Dogri, Dutch, English, Estonian, Faroese, Finnish, French, Galician, Georgian, German, Greek, Gujarati, Haryanvi, Hindi, Hungarian, Indonesian, Irish, Italian, Japanese, Javanese, Kannada, Kashmiri, Kazakh, Konkani, Korean, Kyrgyz, Latvian, Lithuanian, Macedonian, Maithili, Malay, Maltese, Mandarin, Mandarin Chinese, Marathi, Marwari, Min Nan, Moldovan, Mongolian, Montenegrin, Nepali, Norwegian, Oriya, Pashto, Persian (Farsi), Polish, Portuguese, Punjabi, Rajasthani, Romanian, Russian, Sanskrit, Santali, Serbian, Sindhi, Sinhala, Slovak, Slovene, Slovenian, Spanish, Swahili, Swedish, Tajik, Tamil, Tatar, Telugu, Thai, Turkish, Turkmen, Ukrainian, Urdu, Uzbek, Vietnamese, Welsh, and Wu.
- chatdolphin: It works best in English.
- dolphin-yi-34b: It works best in English.
- dolphin-mixtral-8x7b: It works best in English.
HTTP Request
POST https://api.nlpcloud.io/v1/gpu/<model>/code-generation
POST Values
These values must be encoded as JSON.
| Key | Type | Description |
|---|---|---|
instruction |
string | The description of what your program should do. 256 tokens maximum. |
Output
This endpoint returns a JSON object containing the following elements:
| Key | Type | Description |
|---|---|---|
generated_code |
string | The generation source code. |
Dependencies
Input:
curl "https://api.nlpcloud.io/v1/<model_name>/dependencies" \
-H "Authorization: Token <token>" \
-H "Content-Type: application/json" \
-X POST \
-d '{"text":"John Doe is a Go Developer at Google"}'
import nlpcloud
client = nlpcloud.Client("<model_name>", "<token>")
# Returns a json object.
client.dependencies("John Doe is a Go Developer at Google")
require 'nlpcloud'
client = NLPCloud::Client.new('<model_name>','<token>')
# Returns a json object.
client.dependencies("John Doe is a Go Developer at Google")
import (
"net/http"
"github.com/nlpcloud/nlpcloud-go"
)
func main() {
client := nlpcloud.NewClient(&http.Client{}, nlpcloud.ClientParams{Model:"<model_name>", Token:"<token>",
GPU:false, Lang:"", Async:false})
// Returns a Dependencies struct.
dependencies, err := client.Dependencies(nlpcloud.DependenciesParams{
Text: "John Doe is a Go Developer at Google",
})
...
}
const NLPCloudClient = require('nlpcloud');
const client = new NLPCloudClient({model:'<model_name>',token:'<token>'})
// Returns an Axios promise with the results.
// In case of success, results are contained in `response.data`.
// In case of failure, you can retrieve the status code in `err.response.status`
// and the error message in `err.response.data.detail`.
client.dependencies({text:'John Doe is a Go Developer at Google'}).then(function (response) {
console.log(response.data);
})
.catch(function (err) {
console.error(err.response.status);
console.error(err.response.data.detail);
});
require 'vendor/autoload.php';
use NLPCloud\NLPCloud;
$client = new \NLPCloud\NLPCloud('<model_name>','<token>');
# Returns a json object.
echo json_encode($client->dependencies("John Doe is a Go Developer at Google"));
Output (using en_core_web_lg for the example):
{
"words": [
{
"text": "John",
"tag": "NNP"
},
{
"text": "Doe",
"tag": "NNP"
},
{
"text": "is",
"tag": "VBZ"
},
{
"text": "a",
"tag": "DT"
},
{
"text": "Go",
"tag": "NNP"
},
{
"text": "Developer",
"tag": "NN"
},
{
"text": "at",
"tag": "IN"
},
{
"text": "Google",
"tag": "NNP"
}
],
"arcs": [
{
"start": 0,
"end": 1,
"label": "compound",
"text": "John",
"dir": "left"
},
{
"start": 1,
"end": 2,
"label": "nsubj",
"text": "Doe",
"dir": "left"
},
{
"start": 3,
"end": 5,
"label": "det",
"text": "a",
"dir": "left"
},
{
"start": 4,
"end": 5,
"label": "compound",
"text": "Go",
"dir": "left"
},
{
"start": 2,
"end": 5,
"label": "attr",
"text": "Developer",
"dir": "right"
},
{
"start": 5,
"end": 6,
"label": "prep",
"text": "at",
"dir": "right"
},
{
"start": 6,
"end": 7,
"label": "pobj",
"text": "Google",
"dir": "right"
}
]
}
This endpoint uses any spaCy model (it can be either a spaCy pre-trained model or your own spaCy custom model), or Megagon Lab's Ginza model for Japanese, to perform Part-of-Speech (POS) tagging in many languages and returns dependencies (arcs) extracted from the passed in text.
See the spaCy dependency parsing documentation for more details.
If you are using Megagon Lab's Ginza model for Japanese, see the documentation here.
Here are all the spaCy models you can use in multiple languages (see the models section for more details) :
- en_core_web_lg: spaCy large English
- ja_ginza_electra: Ginza Electra Japanese
- ja_core_news_lg: spaCy large Japanese
- fr_core_news_lg: spaCy large French
- zh_core_web_lg: spaCy large Chinese
- da_core_news_lg: spaCy large Danish
- nl_core_news_lg: spaCy large Dutch
- de_core_news_lg: spaCy large German
- el_core_news_lg: spaCy large Greek
- it_core_news_lg: spaCy large Italian
- lt_core_news_lg: spaCy large Lithuanian
- nb_core_news_lg: spaCy large Norwegian okmål
- pl_core_news_lg: spaCy large Polish
- pt_core_news_lg: spaCy large Portuguese
- ro_core_news_lg: spaCy large Romanian
- es_core_news_lg: spaCy large Spanish
Each spaCy or Ginza pre-trained model has a list of supported built-in part-of-speech tags and dependency labels. For example, the list of tags and dependency labels for the en_core_web_lg model can be found here:
- Tags: $, '', ,, -LRB-, -RRB-, ., :, ADD, AFX, CC, CD, DT, EX, FW, HYPH, IN, JJ, JJR, JJS, LS, MD, NFP, NN, NNP, NNPS, NNS, PDT, POS, PRP, PRP$, RB, RBR, RBS, RP, SYM, TO, UH, VB, VBD, VBG, VBN, VBP, VBZ, WDT, WP, WP$, WRB, XX, ``
- Dependency labels: ROOT, acl, acomp, advcl, advmod, agent, amod, appos, attr, aux, auxpass, case, cc, ccomp, compound, conj, csubj, csubjpass, dative, dep, det, dobj, expl, intj, mark, meta, neg, nmod, npadvmod, nsubj, nsubjpass, nummod, oprd, parataxis, pcomp, pobj, poss, preconj, predet, prep, prt, punct, quantmod, relcl, xcomp
For more details about what these abbreviations mean, see spaCy's glossary.
HTTP Request
POST https://api.nlpcloud.io/v1/<model_name>/dependencies
POST Values
These values must be encoded as JSON.
| Key | Type | Description |
|---|---|---|
text |
string | The sentence of text you want to analyze. 350 tokens maximum. |
Output
This endpoint returns 2 objects: words and arcs.
words contains an array of the following elements:
| Key | Type | Description |
|---|---|---|
text |
string | The content of the word |
tag |
string | The part of speech tag for the word (https://spacy.io/api/annotation#pos-tagging) |
arcs contains an array of the following elements:
| Key | Type | Description |
|---|---|---|
text |
string | The content of the word |
label |
string | The syntactic dependency connecting child to head (https://spacy.io/api/annotation#pos-tagging) |
start |
integer | Position of the word if direction of the arc is left. Position of the head if direction of the arc is right. |
end |
integer | Position of the head if direction of the arc is left. Position of the word if direction of the arc is right. |
dir |
string | Direction of the dependency arc (left or right) |
Embeddings
Input:
curl "https://api.nlpcloud.io/v1/<model name>/embeddings" \
-H "Authorization: Token <token>" \
-H "Content-Type: application/json" \
-X POST \
-d '{"sentences":["John Does works for Google.","Janette Doe works for Microsoft.","Janie Does works for NLP Cloud."]}'
import nlpcloud
client = nlpcloud.Client("<model_name>", "<token>")
# Returns json object.
client.embeddings(["John Does works for Google.","Janette Doe works for Microsoft.","Janie Does works for NLP Cloud."])
require 'nlpcloud'
client = NLPCloud::Client.new('<model_name>','<token>')
# Returns a json object.
client.embeddings(["John Does works for Google.","Janette Doe works for Microsoft.","Janie Does works for NLP Cloud."])
import (
"net/http"
"github.com/nlpcloud/nlpcloud-go"
)
func main() {
client := nlpcloud.NewClient(&http.Client{}, nlpcloud.ClientParams{Model:"<model_name>", Token:"<token>",
GPU:false, Lang:"", Async:false})
// Returns an Embeddings struct.
embeddings, err := client.Embeddings(nlpcloud.EmbeddingsParams{
Sentences: []string{"John Does works for Google.","Janette Doe works for Microsoft.","Janie Does works for NLP Cloud."},
})
...
}
const NLPCloudClient = require('nlpcloud');
const client = new NLPCloudClient({model:'<model_name>',token:'<token>'})
// Returns an Axios promise with the results.
// In case of success, results are contained in `response.data`.
// In case of failure, you can retrieve the status code in `err.response.status`
// and the error message in `err.response.data.detail`.
client.embeddings({sentences:'<Text 1>', '<Text 2>', '<Text 3>', ...]}).then(function (response) {
console.log(response.data);
})
.catch(function (err) {
console.error(err.response.status);
console.error(err.response.data.detail);
});
require 'vendor/autoload.php';
use NLPCloud\NLPCloud;
$client = new \NLPCloud\NLPCloud('<model_name>','<token>');
# Returns a json object.
echo json_encode($client->embeddings(array("<Text 1>", "<Text 2>", "<Text 3>", ...)));
Output:
{
"embeddings": [
[0.0927242711186409,-0.19866740703582764,...,-0.013638739474117756,],
[0.03159608319401741,0.021390020847320557,...,0.1698218137025833],
...
[0.027558118104934692,0.06297887861728668,...,0.09421529620885849]
]
}
This endpoint calculates word embeddings from several pieces of texts in many languages.
You can use the following model:
- paraphrase-multilingual-mpnet-base-v2: Paraphrase Multilingual MPNet Base V2 is a very fast model based on Sentence Transformers that is perfectly suited for embeddings extraction in more than 50 languages (see the full list here).
The endpoint returns a list of vectors. Each vector is a list of floats. See below for the details.
HTTP Request
POST https://api.nlpcloud.io/v1/<model name>/embeddings
POST Values
These values must be encoded as JSON.
| Parameter | Type | Description |
|---|---|---|
| sentences | array of strings | The pieces of text you want to analyze. The array can contain 50 elements maximum. Each element should contain 128 tokens maximum. |
Output
This endpoint returns an embeddings object containing an array of vectors. Each vector is an array of floats:
| Key | Type | Description |
|---|---|---|
embeddings |
array of array of floats | The list of calculated embeddings. |
Entities
Input:
curl "https://api.nlpcloud.io/v1/<model_name>/entities" \
-H "Authorization: Token <token>" \
-H "Content-Type: application/json" \
-X POST \
-d '{"text":"John Doe has been working for Microsoft in Seattle since 1999."}'
import nlpcloud
client = nlpcloud.Client("<model_name>", "<token>")
# Returns a json object.
client.entities("John Doe has been working for Microsoft in Seattle since 1999.")
require 'nlpcloud'
client = NLPCloud::Client.new('<model_name>','<token>')
# Returns a json object.
client.entities("John Doe has been working for Microsoft in Seattle since 1999.")
import (
"net/http"
"github.com/nlpcloud/nlpcloud-go"
)
func main() {
client := nlpcloud.NewClient(&http.Client{}, nlpcloud.ClientParams{Model:"<model_name>", Token:"<token>",
GPU:false, Lang:"", Async:false})
// Returns an Entities struct.
entities, err := client.Entities(nlpcloud.EntitiesParams{
Text: "John Doe has been working for Microsoft in Seattle since 1999.",
})
...
}
const NLPCloudClient = require('nlpcloud');
const client = new NLPCloudClient({model:'<model_name>',token:'<token>'})
// Returns an Axios promise with the results.
// In case of success, results are contained in `response.data`.
// In case of failure, you can retrieve the status code in `err.response.status`
// and the error message in `err.response.data.detail`.
client.entities({text:'John Doe has been working for Microsoft in Seattle since 1999.'}).then(function (response) {
console.log(response.data);
})
.catch(function (err) {
console.error(err.response.status);
console.error(err.response.data.detail);
});
require 'vendor/autoload.php';
use NLPCloud\NLPCloud;
$client = new \NLPCloud\NLPCloud('<model_name>','<token>');
# Returns a json object.
echo json_encode($client->entities("John Doe has been working for Microsoft in Seattle since 1999."));
Output (using en_core_web_lg for the example):
{
"entities": [
{
"start": 0,
"end": 8,
"type": "PERSON",
"text": "John Doe"
},
{
"start": 30,
"end": 39,
"type": "ORG",
"text": "Microsoft"
},
{
"start": 43,
"end": 50,
"type": "GPE",
"text": "Seattle"
},
{
"start": 57,
"end": 61,
"type": "DATE",
"text": "1999"
}
]
}
This performs entity extraction (also known as Named Entity Recognition (NER)), in many languages.
If you are using spaCy, give a block of text to the model and it will try to extract entities from it like persons, organizations, countries... See the list of supported entities below. See the spaCy named entity recognition documentation for more details.
If you are using a generative model, you can let the model extract any kind of entity for you, even if it was not explicitly trained for it. Give a block of text + the entity your are looking for in this text (persons, positions, restaurants, ...) and let the model return the corresponding values if they exist.
If you want more control over your GPT-based entity extraction, you should use the text generation endpoint together with few shot learning. And for the best results, you should fine-tune your own model. You can also use your own custom model.
See this quick video about a comparison between spaCy and generative models for entity extraction: Advanced entity extraction (NER) with GPT-NeoX 20B without annotation, and a comparison with spaCy
Here are all the models you can use:
- finetuned-llama-3-70b: It works very well if you want to extract entities that are not natively supported by spaCy. It natively understands the following languages: Albanian, Arabic, Armenian, Awadhi, Azerbaijani, Bashkir, Basque, Belarusian, Bengali, Bhojpuri, Bosnian, Brazilian Portuguese, Bulgarian, Cantonese (Yue), Catalan, Chhattisgarhi, Chinese, Croatian, Czech, Danish, Dogri, Dutch, English, Estonian, Faroese, Finnish, French, Galician, Georgian, German, Greek, Gujarati, Haryanvi, Hindi, Hungarian, Indonesian, Irish, Italian, Japanese, Javanese, Kannada, Kashmiri, Kazakh, Konkani, Korean, Kyrgyz, Latvian, Lithuanian, Macedonian, Maithili, Malay, Maltese, Mandarin, Mandarin Chinese, Marathi, Marwari, Min Nan, Moldovan, Mongolian, Montenegrin, Nepali, Norwegian, Oriya, Pashto, Persian (Farsi), Polish, Portuguese, Punjabi, Rajasthani, Romanian, Russian, Sanskrit, Santali, Serbian, Sindhi, Sinhala, Slovak, Slovene, Slovenian, Spanish, Swahili, Swedish, Tajik, Tamil, Tatar, Telugu, Thai, Turkish, Turkmen, Ukrainian, Urdu, Uzbek, Vietnamese, Welsh, and Wu.
- en_core_web_lg: very fast entity extraction in English but with only a limited number of supported entities
- ja_ginza_electra: fast entity extraction in Japanese but with only a limited number of supported entities
- ja_core_news_lg: very fast entity extraction in Japanese but with only a limited number of supported entities
- fr_core_news_lg: very fast entity extraction in French but with only a limited number of supported entities
- zh_core_web_lg: very fast entity extraction in Chinese but with only a limited number of supported entities
- da_core_news_lg: very fast entity extraction in Danish but with only a limited number of supported entities
- nl_core_news_lg: very fast entity extraction in Dutch but with only a limited number of supported entities
- de_core_news_lg: very fast entity extraction in German but with only a limited number of supported entities
- el_core_news_lg: very fast entity extraction in Greek but with only a limited number of supported entities
- it_core_news_lg: very fast entity extraction in Italian but with only a limited number of supported entities
- lt_core_news_lg: very fast entity extraction in Lithuanian but with only a limited number of supported entities
- nb_core_news_lg: very fast entity extraction in Norwegian okmål but with only a limited number of supported entities
- pl_core_news_lg: very fast entity extraction in Polish but with only a limited number of supported entities
- pt_core_news_lg: very fast entity extraction in Portuguese but with only a limited number of supported entities
- ro_core_news_lg: very fast entity extraction in Romanian but with only a limited number of supported entities
- es_core_news_lg: very fast entity extraction in Spanish but with only a limited number of supported entities
Each spaCy or Ginza pre-trained model has a fixed list of supported built-in entities it is able to extract. For example, the list of entities for the en_core_web_lg model can be found here:
- ORG: Companies, agencies, institutions, etc.
- DATE: Absolute or relative dates or periods
- EVENT: Named hurricanes, battles, wars, sports events, etc.
- FAC: Buildings, airports, highways, bridges, etc.
- GPE: Countries, cities, states
- LOC: Non-GPE locations, mountain ranges, bodies of water
- MONEY: Monetary values, including unit
- NORP: Nationalities or religious or political groups
- PERCENT: Percentage (including “%”)
- PERSON: People, including fictional
- PRODUCT: Vehicles, weapons, foods, etc. (Not services)
- QUANTITY: Measurements, as of weight or distance
- TIME: Times smaller than a day
- WORK_OF_ART: Titles of books, songs, etc.
- LANGUAGE: Any named language
- LAW: Named documents made into laws
- ORDINAL: “first”, “second”, ...
- CARDINAL: Numerals that do not fall under another type
Here is an example using Postman:
Put your JSON data in Body > raw. Note that if your text contains double quotes (") you will need to escape them (using \") in order for your JSON to be properly decoded. This is not needed when using a client library.
HTTP Request
POST https://api.nlpcloud.io/v1/<model_name>/entities
POST Values
These values must be encoded as JSON.
| Key | Type | Description |
|---|---|---|
text |
string | The sentence you want to analyze. 256 tokens maximum in synchronous mode and 1 million tokens maximum in asynchronous mode. |
searched_entity |
string | Only applies to GPT models, so it will be ignored if you're using spaCy. This is the entity you are looking for. You can use anything, like positions, countries, programming languages, frameworks, restaurant names... If you use a singular you will be more likely to get one single result, while if you use a plural the model will try to extract several entities from the text. |
Output
This endpoint returns a JSON array of entities. Each entity is an object made up of the following:
| Key | Type | Description |
|---|---|---|
text |
string | The content of the entity |
type |
string | The type of entity (person, position, company, etc.) |
start |
integer | The position of the 1st character of the entity (starting at 0) |
end |
integer | The position of the 1st character after the entity |
Generation
Input:
curl "https://api.nlpcloud.io/v1/gpu/<model_name>/generation" \
-H "Authorization: Token <token>" \
-H "Content-Type: application/json" \
-X POST -d '{
"text":"LLaMA is a powerful NLP model",
"max_length":50
}'
import nlpcloud
client = nlpcloud.Client("<model_name>", "<token>", gpu=True)
# Returns a JSON object.
client.generation("LLaMA is a powerful NLP model", max_length=50)
require 'nlpcloud'
client = NLPCloud::Client.new('<model_name>','<token>', gpu: true)
# Returns a json object.
client.generation('LLaMA is a powerful NLP model', max_length: 50)
import (
"net/http"
"github.com/nlpcloud/nlpcloud-go"
)
func main() {
client := nlpcloud.NewClient(&http.Client{}, nlpcloud.ClientParams{Model:"<model_name>", Token:"<token>",
GPU:true})
// Returns a Generation struct.
generatedText, err := client.Generation(nlpcloud.GenerationParams{
Text: "LLaMA is a powerful NLP model",
MaxLength: 50,
})
...
}
const NLPCloudClient = require('nlpcloud');
const client = new NLPCloudClient({model:'<model_name>',token:'<token>',gpu:true})
// Returns an Axios promise with the results.
// In case of success, results are contained in `response.data`.
// In case of failure, you can retrieve the status code in `err.response.status`
// and the error message in `err.response.data.detail`.
client.generation({text:'LLaMA is a powerful NLP model', maxLength:50}).then(function (response) {
console.log(response.data);
})
.catch(function (err) {
console.error(err.response.status);
console.error(err.response.data.detail);
});
require 'vendor/autoload.php';
use NLPCloud\NLPCloud;
$client = new \NLPCloud\NLPCloud('<model_name>','<token>', True);
# Returns a json object.
echo json_encode($client->generation("LLaMA is a powerful NLP model", NULL, 50));
Output:
{
"generated_text":"LLaMA is a powerful NLP model for text generation.
This is the open-source version of GPT-4 by OpenAI. It is the most
advanced NLP model created as of today.",
"nb_generated_tokens": 33,
"nb_input_tokens": 7
}
This endpoint uses several large language models for text generation (these models are generative models equivalent to OpenAI GPT-4 and ChatGPT).
Text generation is for advanced users. Many parameters are available. For instruct models like Fine-tuned LLaMA 3 70B, ChatDolphin, Dolphin Yi 34B, or Dolphin Mixtral 8x7B, you can ask your requests in natural human language. The other models work best with few-shot learning (also known as "prompt engineering"). Many other API endpoints (paraphrasing, intent classification, etc.) also use text generation under the hood but are simpler to use as optimal parameters and prompts are already pre-set.
For text generation in non-English languages, you can use our multilingual add-on. Note that Fine-tuned LLaMA 3 70B natively work quite well in many non English languages without even using the multilingual add-on.
These following models are available:
- finetuned-llama-3-70b: text generation with a fine-tuned version of LLaMA 3 70B that understands human instructions without having to use few-shot learning, but that also works very well with few-shot learning. It supports a 4096 tokens context (input + output). Not all the parameters are supported for the moment. It natively understands the following languages: Albanian, Arabic, Armenian, Awadhi, Azerbaijani, Bashkir, Basque, Belarusian, Bengali, Bhojpuri, Bosnian, Brazilian Portuguese, Bulgarian, Cantonese (Yue), Catalan, Chhattisgarhi, Chinese, Croatian, Czech, Danish, Dogri, Dutch, English, Estonian, Faroese, Finnish, French, Galician, Georgian, German, Greek, Gujarati, Haryanvi, Hindi, Hungarian, Indonesian, Irish, Italian, Japanese, Javanese, Kannada, Kashmiri, Kazakh, Konkani, Korean, Kyrgyz, Latvian, Lithuanian, Macedonian, Maithili, Malay, Maltese, Mandarin, Mandarin Chinese, Marathi, Marwari, Min Nan, Moldovan, Mongolian, Montenegrin, Nepali, Norwegian, Oriya, Pashto, Persian (Farsi), Polish, Portuguese, Punjabi, Rajasthani, Romanian, Russian, Sanskrit, Santali, Serbian, Sindhi, Sinhala, Slovak, Slovene, Slovenian, Spanish, Swahili, Swedish, Tajik, Tamil, Tatar, Telugu, Thai, Turkish, Turkmen, Ukrainian, Urdu, Uzbek, Vietnamese, Welsh, and Wu.
- chatdolphin: text generation with ChatDolphin, an NLP Cloud in-house model based on Dolphin, fine-tuned to understand human instructions without having to use few-shot learning. It supports a 8192 tokens input and a 2048 tokens output. No text generation parameters are supported by this model for the moment, but the "###" end sequence is automatically implemented under the hood in case you want to use few-shot learning. It works best in English.
- dolphin-yi-34b: text generation with Dolphin Yi 34B by Eric Hartford, fine-tuned to understand human instructions without having to use few-shot learning. It supports a 8192 tokens input and a 2048 tokens output. No text generation parameters are supported by this model for the moment, but the "###" end sequence is automatically implemented under the hood in case you want to use few-shot learning. It works best in English.
- dolphin-mixtral-8x7b: text generation with Dolphin Mixtral 8x7B by Eric Hartford, fine-tuned to understand human instructions without having to use few-shot learning. It supports a 8192 tokens input and a 2048 tokens output. No text generation parameters are supported by this model for the moment, but the "###" end sequence is automatically implemented under the hood in case you want to use few-shot learning. It works best in English.
You can achieve almost any use case with a great accuracy either using few-shot learning or natural language instructions. See our few-shot learning examples and our natural language instruction examples. See more use case ideas on the OpenAI website and take time to attend this free 1h prompt engineering class released by DeepLearning.AI.
For advanced text generation tuning, you can play with many parameters like top p, temperature, num_beams, repetition_penalty, etc. They are sometimes a good way to produce more original and fluent content. See the full list of parameters below. If you are not sure what these parameters do, you can also read this very good article from Hugging Face (it's a bit technical though).
Input for streaming request:
curl -N --output - "https://api.nlpcloud.io/v1/gpu/<model_name>/generation" \
-H "Authorization: Token <token>" \
-H "Content-Type: application/json" \
-X POST -d '{
"text":"LLaMA is a powerful NLP model",
"max_length":50,
"stream":true
}'
# Not implemented yet but here is how you can achieve it with
# the Requests library
import requests
url = "https://api.nlpcloud.io/v1/gpu/<model_name>/generation"
headers = {
"Authorization": "Token <token>",
"Content-Type": "application/json",
}
data = {
"text": "LLaMA is a powerful NLP model",
"stream": True,
}
r = requests.post(url, headers=headers, json=data, stream=True)
for line in r.iter_lines():
if line:
decoded_line = line.decode('utf-8')
print(decoded_line)
# Not implemented yet
client := nlpcloud.NewClient(&http.Client{}, nlpcloud.ClientParams{Model: <model_name>, Token: <token>, GPU: true})
streamBody, err := client.StreamingGeneration(nlpcloud.GenerationParams{
Text: "LLaMA is a powerful NLP model",
MaxLength: 50,
})
if err != nil {
log.Fatalln(err)
}
defer streamBody.Close()
stream := bufio.NewReader(streamBody)
for {
chunk, err := stream.ReadBytes('\x00')
if err != nil {
if errors.Is(err, io.EOF) {
break
}
log.Fatalln()
}
fmt.Println(string(chunk))
}
// Not implemented yet
// Not implemented yet
SSE output:
LLaMA is a powerful NLP model for text generation.
This is the open-source version of GPT-4 by OpenAI. It is the most
advanced NLP model created as of today.[DONE]
If you want the text to appear gradually as soon as it is generated (also known as "token streaming") you can use the stream parameter.
You can also train/fine-tune your own Dolphin, Yi 34B, and Mixtral 8x7B models if few-shot learning is not meeting your expectations.
Here is an example using Postman:
Put your JSON data in Body > raw. Note that if your text contains double quotes (") you will need to escape them (using \") in order for your JSON to be properly decoded. This is not needed when using a client library.
HTTP Request
POST https://api.nlpcloud.io/v1/<model_name>/generation
POST Values
These values must be encoded as JSON.
| Key | Type | Description |
|---|---|---|
text |
string | The block of text that starts the generated text. 4096 tokens for Fine-tuned LLaMA 3 70B and 8192 for the other models. |
max_length |
int | Optional. The maximum number of tokens that the generated text should contain. 4096 tokens for Fine-tuned LLaMA 3 70B and 2048 tokens for the other models. If length_no_input is false, the size of the generated text is the difference between max_length and the length of your input text. If length_no_input is true, the size of the generated text simply is max_length. Defaults to 50. Not supported by ChatDolphin, Dolphin Yi 34B, and Dolphin Mixtral 8x7B. |
length_no_input |
bool | Optional. Whether min_length and max_length should not include the length of the input text. If false, min_length and max_length include the length of the input text. If true, min_length and max_length don't include the length of the input text. Defaults to false. Not supported by ChatDolphin, Dolphin Yi 34B, and Dolphin Mixtral 8x7B. |
end_sequence |
string | Optional. A specific token that should be the end of the generated sequence. For example if could be ., or \n, or ### or anything else below 10 characters. Not supported by ChatDolphin, Dolphin Yi 34B, and Dolphin Mixtral 8x7B. |
remove_end_sequence |
bool | Optional. Whether you want to remove the end_sequence string from the result. Defaults to false. Not supported by ChatDolphin, Dolphin Yi 34B, and Dolphin Mixtral 8x7B. |
remove_input |
bool | Optional. Whether you want to remove the input text from the result. Defaults to false. Not supported by ChatDolphin, Dolphin Yi 34B, and Dolphin Mixtral 8x7B. |
temperature |
float | Optional. Temperature sampling. It modules the next token probabilities. The higher this value, the less deterministic the result will be. If set to zero, no sampling will be applied at all and greedy search will apply instead. For example if temperature=0 the output will always be the same, while if temperature=1 each new request will produce very different results. It is recommended to play with top_p if you want to produce original content for applications that require accurate results, while you should use temperature if you want to generate more funny results. You should not use both at the same time. Should be between 0 and 1000. Defaults to 0.8. Not supported by ChatDolphin, Dolphin Yi 34B, and Dolphin Mixtral 8x7B. |
top_p |
float | Optional. Top P sampling. Below 1, only the most probable tokens with probabilities that add up to top_p or higher are kept for generation. The higher this value, the less deterministic the result will be. It's recommended to play with top_p if you want to produce original content for applications that require accurate results, while you should use temperature if you want to generate more funny results. You should not use both at the same time. Should be between 0 and 1. Defaults to 1.0. Not supported by ChatDolphin, Dolphin Yi 34B, and Dolphin Mixtral 8x7B. |
top_k |
int | Optional. Top K sampling. The number of highest probability vocabulary tokens to keep for top k filtering. The lower this value, the less the model is going to generate off-topic text. Should be between 1 and 1000. Defaults to 50. Not supported by ChatDolphin, Dolphin Yi 34B, and Dolphin Mixtral 8x7B. |
repetition_penalty |
float | Optional. Prevents the same word from being repeated too many times. 1.0 means no penalty. Above 1.0, repetitions are less likely to happen. Below 1.0, repetitions are more likely to happen. Should be between -1.0 and 3.0. Defaults to 1.0. Not supported by ChatDolphin, Dolphin Yi 34B, and Dolphin Mixtral 8x7B. |
num_beams |
int | Optional. Number of beams for beam search. 1 means no beam search. If num_beams > 1, beam search will apply. If num_beams > 1, the size of the input text should not exceed 60 tokens. Should be between 1 and 20. Defaults to 1. Not supported by ChatDolphin, Dolphin Yi 34B, and Dolphin Mixtral 8x7B. |
num_return_sequences |
int | Optional. The number of independently computed returned sequences. Should be between 1 and 50. Defaults to 1. Not supported by ChatDolphin, Dolphin Yi 34B, and Dolphin Mixtral 8x7B. |
stream |
bool | Optional. Whether the response should be streamed. Defaults to false. |
Output
If stream is set to false, this endpoint returns a JSON object containing the following elements:
| Key | Type | Description |
|---|---|---|
generated_text |
string | The generated text |
nb_generated_tokens |
int | The number of tokens generated by the model |
nb_input_tokens |
int | The number of tokens sent to the model |
If stream is set to true, the endpoint returns the generated text as raw text through server sent events (SSE). Once the generation is finished, the endpoint returns "[DONE]". Note that in that case the number of input tokens and generated tokens are not returned.
Grammar and Spelling Correction
Input:
curl "https://api.nlpcloud.io/v1/gpu/<model>/gs-correction" \
-H "Authorization: Token <token>" \
-H "Content-Type: application/json" \
-X POST -d '{"text":"Two month after the United States begun what has become a troubled rollout of a national COVID vaccination campaign, the effort is finaly gathering real steam."}'
import nlpcloud
client = nlpcloud.Client("<model>", "<token>", True)
# Returns a json object.
client.gs_correction("Two month after the United States begun what has become a troubled rollout of a national COVID vaccination campaign, the effort is finaly gathering real steam.")
require 'nlpcloud'
client = NLPCloud::Client.new('<model_name>','<token>', gpu: true)
# Returns a json object.
client.gs_correction('Two month after the United States begun what has become a troubled rollout of a national COVID vaccination campaign, the effort is finaly gathering real steam.')
import (
"net/http"
"github.com/nlpcloud/nlpcloud-go"
)
func main() {
client := nlpcloud.NewClient(&http.Client{}, nlpcloud.ClientParams{Model:"<model_name>", Token:"<token>",
GPU:true, Lang:"", Async:false})
// Returns a GSCorrection struct.
gSCorrection, err := client.GSCorrection(nlpcloud.GSCorrectionParams{
Text: "Two month after the United States begun what has become a troubled rollout of a national COVID vaccination campaign, the effort is finaly gathering real steam.",
})
...
}
const NLPCloudClient = require('nlpcloud');
const client = new NLPCloudClient({model:'<model_name>',token:'<token>',gpu:true})
// Returns an Axios promise with the results.
// In case of success, results are contained in `response.data`.
// In case of failure, you can retrieve the status code in `err.response.status`
// and the error message in `err.response.data.detail`.
client.gsCorrection({text:'Two month after the United States begun what has become a troubled rollout of a national COVID vaccination campaign, the effort is finaly gathering real steam.'}).then(function (response) {
console.log(response.data);
})
.catch(function (err) {
console.error(err.response.status);
console.error(err.response.data.detail);
});
require 'vendor/autoload.php';
use NLPCloud\NLPCloud;
$client = new \NLPCloud\NLPCloud('<model_name>','<token>', True);
# Returns a json object.
echo json_encode($client->gsCorrection("Two month after the United States begun what has become a troubled rollout of a national COVID vaccination campaign, the effort is finaly gathering real steam."));
Output:
{
"correction": "Two months after the United States began what has become a troubled rollout of a national COVID vaccination campaign, the effort is finally gathering real steam."
}
This endpoint performs grammar and spelling correction. The model takes your input and returns the same thing, but without any mistake.
For non-English languages, you can use our multilingual add-on but that Fine-tuned LLaMA 3 70B natively works quite well in many non English languages without even using the multilingual add-on.
If you want more control over this task, you should use the text generation endpoint together with few shot learning. And for the best results, you should fine-tune your own model. You can also use your own custom model.
You can use the following models:
- finetuned-llama-3-70b: It natively understands the following languages: Albanian, Arabic, Armenian, Awadhi, Azerbaijani, Bashkir, Basque, Belarusian, Bengali, Bhojpuri, Bosnian, Brazilian Portuguese, Bulgarian, Cantonese (Yue), Catalan, Chhattisgarhi, Chinese, Croatian, Czech, Danish, Dogri, Dutch, English, Estonian, Faroese, Finnish, French, Galician, Georgian, German, Greek, Gujarati, Haryanvi, Hindi, Hungarian, Indonesian, Irish, Italian, Japanese, Javanese, Kannada, Kashmiri, Kazakh, Konkani, Korean, Kyrgyz, Latvian, Lithuanian, Macedonian, Maithili, Malay, Maltese, Mandarin, Mandarin Chinese, Marathi, Marwari, Min Nan, Moldovan, Mongolian, Montenegrin, Nepali, Norwegian, Oriya, Pashto, Persian (Farsi), Polish, Portuguese, Punjabi, Rajasthani, Romanian, Russian, Sanskrit, Santali, Serbian, Sindhi, Sinhala, Slovak, Slovene, Slovenian, Spanish, Swahili, Swedish, Tajik, Tamil, Tatar, Telugu, Thai, Turkish, Turkmen, Ukrainian, Urdu, Uzbek, Vietnamese, Welsh, and Wu.
- chatdolphin: It works best in English.
- dolphin-yi-34b: It works best in English.
- dolphin-mixtral-8x7b: It works best in English.
HTTP Request
POST https://api.nlpcloud.io/v1/gpu/<model_name>/gs-correction
POST Values
These values must be encoded as JSON.
| Key | Type | Description |
|---|---|---|
text |
string | The text you want to correct. 256 tokens maximum in synchronous mode and 1 million tokens maximum in asynchronous mode. |
Output
This endpoint returns a JSON object containing the following elements:
| Key | Type | Description |
|---|---|---|
correction |
string | The corrected text. |
Image Generation
Input:
curl "https://api.nlpcloud.io/v1/gpu/stable-diffusion/image-generation" \
-H "Authorization: Token <token>" \
-H "Content-Type: application/json" \
-X POST -d '{"text":"An oil painting of a fox walking in the snow."}'
import nlpcloud
client = nlpcloud.Client("stable-diffusion", "<token>", True)
# Returns a json object.
client.image_generation("""An oil painting of a fox walking in the snow.""")
require 'nlpcloud'
client = NLPCloud::Client.new('stable-diffusion','<token>', gpu: true)
# Returns a json object.
client.image_generation("An oil painting of a fox walking in the snow.")
import (
"net/http"
"github.com/nlpcloud/nlpcloud-go"
)
func main() {
client := nlpcloud.NewClient(&http.Client{}, nlpcloud.ClientParams{Model:"stable-diffusion", Token:"<token>",
GPU:true, Lang:"", Async:false})
// Returns an ImageGeneration struct.
image, err := client.imageGeneration(nlpcloud.ImageGenerationParams{
Text: "An oil painting of a fox walking in the snow.",
})
...
}
const NLPCloudClient = require('nlpcloud');
const client = new NLPCloudClient({model:'stable-diffusion',token:'<token>',gpu:true})
// Returns an Axios promise with the results.
// In case of success, results are contained in `response.data`.
// In case of failure, you can retrieve the status code in `err.response.status`
// and the error message in `err.response.data.detail`.
client.imageGeneration({text:'An oil painting of a fox walking in the snow.'}).then(function (response) {
console.log(response.data);
})
.catch(function (err) {
console.error(err.response.status);
console.error(err.response.data.detail);
});
require 'vendor/autoload.php';
use NLPCloud\NLPCloud;
$client = new \NLPCloud\NLPCloud('stable-diffusion','<token>',True);
# Returns a json object.
echo json_encode($client->imageGeneration("An oil painting of a fox walking in the snow."));
Output:
{
"url": "https://d2pgcgj5ldlmy6.cloudfront.net/d718942adee743f698ca8b5f5ff8474e.png"
}
This endpoint uses Stability AI's Stable Diffusion XL model to generate a 1024x1024 px image out of a simple text instruction. Once generated, the image is automatically stored on a Cloudfront CDN and a URL to the image is returned. You can then use the URL to download the image or embed it in your application.
In order to make the most of Stable Diffusion, read this article that shows various text to image techniques.
For image generation in non-English languages, please use our multilingual add-on.
Pass a couple of words or a whole paragraph, and the model will generate an image out of it.
Here is the model you can use:
- stable-diffusion for image generation in English.
HTTP Request
POST https://api.nlpcloud.io/v1/gpu/stable-diffusion/image-generation
POST Values
These values must be encoded as JSON.
| Key | Type | Description |
|---|---|---|
text |
string | Your text instruction for image generation. 77 tokens maximum. |
Output
This endpoint returns a JSON object containing the following elements:
| Key | Type | Description |
|---|---|---|
url |
string | The URL to the generated image, hosted on a Cloudfront CDN |
Intent Classification
Input:
curl "https://api.nlpcloud.io/v1/gpu/<model_name>/intent-classification" \
-H "Authorization: Token <token>" \
-H "Content-Type: application/json" \
-X POST -d '{"text":"Hello\nI spent some time on your documentation but I could not figure how to add a new credit card.\nIt is a problem because my current card is going to expire soon and I am affraid that it will cause a service disruption.\nHow can I update my credit card?\nThanks in advance,\nLooking forward to hearing from you,\nJohn Doe"}'
import nlpcloud
client = nlpcloud.Client("<model_name>", "<token>", True)
# Returns a json object.
client.intent_classification("Hello\nI spent some time on your documentation but I could not figure how to add a new credit card.\nIt is a problem because my current card is going to expire soon and I am affraid that it will cause a service disruption.\nHow can I update my credit card?\nThanks in advance,\nLooking forward to hearing from you,\nJohn Doe")
require 'nlpcloud'
client = NLPCloud::Client.new('<model_name>','<token>', gpu: true)
# Returns a json object.
client.intent_classification('Hello\nI spent some time on your documentation but I could not figure how to add a new credit card.\nIt is a problem because my current card is going to expire soon and I am affraid that it will cause a service disruption.\nHow can I update my credit card?\nThanks in advance,\nLooking forward to hearing from you,\nJohn Doe')
import (
"net/http"
"github.com/nlpcloud/nlpcloud-go"
)
func main() {
client := nlpcloud.NewClient(&http.Client{}, nlpcloud.ClientParams{Model:"<model_name>", Token:"<token>",
GPU:true, Lang:"", Async:false})
// Returns an IntentClassification struct.
intentClassification, err := client.IntentClassification(nlpcloud.IntentClassificationParams{
Text: "Hello\nI spent some time on your documentation but I could not figure how to add a new credit card.\nIt is a problem because my current card is going to expire soon and I am affraid that it will cause a service disruption.\nHow can I update my credit card?\nThanks in advance,\nLooking forward to hearing from you,\nJohn Doe",
})
...
}
const NLPCloudClient = require('nlpcloud');
const client = new NLPCloudClient({model:'<model_name>',token:'<token>',gpu:true})
// Returns an Axios promise with the results.
// In case of success, results are contained in `response.data`.
// In case of failure, you can retrieve the status code in `err.response.status`
// and the error message in `err.response.data.detail`.
client.intentClassification(text:'Hello\nI spent some time on your documentation but I could not figure how to add a new credit card.\nIt is a problem because my current card is going to expire soon and I am affraid that it will cause a service disruption.\nHow can I update my credit card?\nThanks in advance,\nLooking forward to hearing from you,\nJohn Doe'}).then(function (response) {
console.log(response.data);
})
.catch(function (err) {
console.error(err.response.status);
console.error(err.response.data.detail);
});
require 'vendor/autoload.php';
use NLPCloud\NLPCloud;
$client = new \NLPCloud\NLPCloud('<model_name>','<token>', True);
# Returns a json object.
echo json_encode($client->intentClassification("Hello\nI spent some time on your documentation but I could not figure how to add a new credit card.\nIt is a problem because my current card is going to expire soon and I am affraid that it will cause a service disruption.\nHow can I update my credit card?\nThanks in advance,\nLooking forward to hearing from you,\nJohn Doe"));
Output:
{
"intent": "update credit card"
}
The endpoint tries to detect what is the main intent in the text.
For intent classification in non-English languages, please use our multilingual add-on, but note that Fine-tuned LLaMA 3 70B natively works quite well in many non English languages without even using the multilingual add-on.
If you want more control over the intent classification, you should use the text generation endpoint together with few shot learning. And for the best results, you should fine-tune your own model. You can also use your own custom model.
The following models are available:
- finetuned-llama-3-70b: It natively understands the following languages: Albanian, Arabic, Armenian, Awadhi, Azerbaijani, Bashkir, Basque, Belarusian, Bengali, Bhojpuri, Bosnian, Brazilian Portuguese, Bulgarian, Cantonese (Yue), Catalan, Chhattisgarhi, Chinese, Croatian, Czech, Danish, Dogri, Dutch, English, Estonian, Faroese, Finnish, French, Galician, Georgian, German, Greek, Gujarati, Haryanvi, Hindi, Hungarian, Indonesian, Irish, Italian, Japanese, Javanese, Kannada, Kashmiri, Kazakh, Konkani, Korean, Kyrgyz, Latvian, Lithuanian, Macedonian, Maithili, Malay, Maltese, Mandarin, Mandarin Chinese, Marathi, Marwari, Min Nan, Moldovan, Mongolian, Montenegrin, Nepali, Norwegian, Oriya, Pashto, Persian (Farsi), Polish, Portuguese, Punjabi, Rajasthani, Romanian, Russian, Sanskrit, Santali, Serbian, Sindhi, Sinhala, Slovak, Slovene, Slovenian, Spanish, Swahili, Swedish, Tajik, Tamil, Tatar, Telugu, Thai, Turkish, Turkmen, Ukrainian, Urdu, Uzbek, Vietnamese, Welsh, and Wu.
- chatdolphin: It works best in English.
- dolphin-yi-34b: It works best in English.
- dolphin-mixtral-8x7b: It works best in English.
HTTP Request
POST https://api.nlpcloud.io/v1/gpu/<model>/intent-classification
POST Values
These values must be encoded as JSON.
| Key | Type | Description |
|---|---|---|
text |
string | The text you want to detect intent from. 4096 tokens for Fine-tuned LLaMA 3 70B and 8192 tokens for the other models. |
Output
This endpoint returns a JSON object containing the following elements:
| Key | Type | Description |
|---|---|---|
intent |
string | The main intent hidden in your text. |
Keywords and Keyphrases Extraction
Input:
curl "https://api.nlpcloud.io/v1/gpu/<model>/kw-kp-extraction" \
-H "Authorization: Token <token>" \
-H "Content-Type: application/json" \
-X POST -d '{"text":"One month after the United States began what has become a troubled rollout of a national COVID vaccination campaign, the effort is finally gathering real steam."}'
import nlpcloud
client = nlpcloud.Client("<model>", "<token>", True)
# Returns a json object.
client.kw_kp_extraction("One month after the United States began what has become a troubled rollout of a national COVID vaccination campaign, the effort is finally gathering real steam.")
require 'nlpcloud'
client = NLPCloud::Client.new('<model_name>','<token>', gpu: true)
# Returns a json object.
client.kw_kp_extraction('One month after the United States began what has become a troubled rollout of a national COVID vaccination campaign, the effort is finally gathering real steam.')
import (
"net/http"
"github.com/nlpcloud/nlpcloud-go"
)
func main() {
client := nlpcloud.NewClient(&http.Client{}, nlpcloud.ClientParams{Model:"<model_name>", Token:"<token>",
GPU:true, Lang:"", Async:false})
// Returns an KwKpExtraction struct.
kwKpExtraction, err := client.KwKpExtraction(nlpcloud.KwKpExtractionParams{
Text: "One month after the United States began what has become a troubled rollout of a national COVID vaccination campaign, the effort is finally gathering real steam.",
})
...
}
const NLPCloudClient = require('nlpcloud');
const client = new NLPCloudClient({model:'<model_name>',token:'<token>',gpu:true})
// Returns an Axios promise with the results.
// In case of success, results are contained in `response.data`.
// In case of failure, you can retrieve the status code in `err.response.status`
// and the error message in `err.response.data.detail`.
client.kwKpExtraction({text:'One month after the United States began what has become a troubled rollout of a national COVID vaccination campaign, the effort is finally gathering real steam.'}).then(function (response) {
console.log(response.data);
})
.catch(function (err) {
console.error(err.response.status);
console.error(err.response.data.detail);
});
require 'vendor/autoload.php';
use NLPCloud\NLPCloud;
$client = new \NLPCloud\NLPCloud('<model_name>','<token>', True);
# Returns a json object.
echo json_encode($client->kwKpExtraction("One month after the United States began what has become a troubled rollout of a national COVID vaccination campaign, the effort is finally gathering real steam."));
Output:
{
"keywords_and_keyphrases": ["COVID","vaccination","United States"]
}
This endpoint performs keywords and keyphrases extraction. The model extracts the main ideas from your text. These ideas can be keywords or a couple of keywords (also known as keyphrases).
For keywords and keyphrases extraction in non-English languages, you can use our multilingual add-on. Note that Fine-tuned LLaMA 3 70B works natively in many non English languages without even using the multilingual add-on.
If you want more control over the keywords and keyphrases extraction, you should use the text generation endpoint together with few shot learning. And for the best results, you should fine-tune your own model. You can also use your own custom model.
You can use the following models:
- finetuned-llama-3-70b: It natively understands the following languages: Albanian, Arabic, Armenian, Awadhi, Azerbaijani, Bashkir, Basque, Belarusian, Bengali, Bhojpuri, Bosnian, Brazilian Portuguese, Bulgarian, Cantonese (Yue), Catalan, Chhattisgarhi, Chinese, Croatian, Czech, Danish, Dogri, Dutch, English, Estonian, Faroese, Finnish, French, Galician, Georgian, German, Greek, Gujarati, Haryanvi, Hindi, Hungarian, Indonesian, Irish, Italian, Japanese, Javanese, Kannada, Kashmiri, Kazakh, Konkani, Korean, Kyrgyz, Latvian, Lithuanian, Macedonian, Maithili, Malay, Maltese, Mandarin, Mandarin Chinese, Marathi, Marwari, Min Nan, Moldovan, Mongolian, Montenegrin, Nepali, Norwegian, Oriya, Pashto, Persian (Farsi), Polish, Portuguese, Punjabi, Rajasthani, Romanian, Russian, Sanskrit, Santali, Serbian, Sindhi, Sinhala, Slovak, Slovene, Slovenian, Spanish, Swahili, Swedish, Tajik, Tamil, Tatar, Telugu, Thai, Turkish, Turkmen, Ukrainian, Urdu, Uzbek, Vietnamese, Welsh, and Wu.
HTTP Request
POST https://api.nlpcloud.io/v1/gpu/<model_name>/kw-kp-extraction
POST Values
These values must be encoded as JSON.
| Key | Type | Description |
|---|---|---|
text |
string | The text you want to extract keywords and keyphrases from. 1024 tokens maximum in synchronous mode and 1 million tokens maximum in asynchronous mode. |
Output
This endpoint returns a JSON object containing the following elements:
| Key | Type | Description |
|---|---|---|
keywords_and_keyphrases |
string | The main keywords and keyphrases in your text. |
Language Detection
Input:
curl "https://api.nlpcloud.io/v1/python-langdetect/langdetection" \
-H "Authorization: Token <token>" \
-H "Content-Type: application/json" \
-X POST -d '{"text":"John Doe has been working for Microsoft in Seattle since 1999. Et il parle aussi un peu français."}'
import nlpcloud
client = nlpcloud.Client("python-langdetect", "<token>")
# Returns a json object.
client.langdetection("John Doe has been working for Microsoft in Seattle since 1999. Et il parle aussi un peu français.")
require 'nlpcloud'
client = NLPCloud::Client.new('python-langdetect','<token>')
# Returns a json object.
client.langdetection("John Doe has been working for Microsoft in Seattle since 1999. Et il parle aussi un peu français.")
import (
"net/http"
"github.com/nlpcloud/nlpcloud-go"
)
func main() {
client := nlpcloud.NewClient(&http.Client{}, nlpcloud.ClientParams{Model:"<model_name>", Token:"<token>",
GPU:false, Lang:"", Async:false})
// Returns a LangDetection object.
languages, err := client.LangDetection(nlpcloud.LangDetectionParams{
Text: `John Doe has been working for Microsoft in Seattle since 1999.
Et il parle aussi un peu français.`,
})
...
}
const NLPCloudClient = require('nlpcloud');
const client = new NLPCloudClient({model:'python-langdetect',token:'<token>'})
// Returns an Axios promise with the results.
// In case of success, results are contained in `response.data`.
// In case of failure, you can retrieve the status code in `err.response.status`
// and the error message in `err.response.data.detail`.
client.langdetection({text:`John Doe has been working for Microsoft in Seattle since 1999. Et il parle aussi un peu français.`}).then(function (response) {
console.log(response.data);
})
.catch(function (err) {
console.error(err.response.status);
console.error(err.response.data.detail);
});
require 'vendor/autoload.php';
use NLPCloud\NLPCloud;
$client = new \NLPCloud\NLPCloud('python-langdetect','<token>');
# Returns a json object.
echo json_encode($client->langdetection("John Doe has been working for Microsoft in Seattle since 1999. Et il parle aussi un peu français."));
Output:
{
"languages": [
{
"en": 0.7142834369645996
},
{
"fr": 0.28571521669868466
}
]
}
This endpoint uses Python's LangDetect library to detect languages from a text. It returns an array with all the languages detected in the text and their likelihood. The results are sorted by likelihood, so the first language in the array is the most likely. The languages follow the 2 characters ISO codes.
This endpoint is not using deep learning under the hood so the response time is extremely fast.
Here is an example of language detection using Postman:
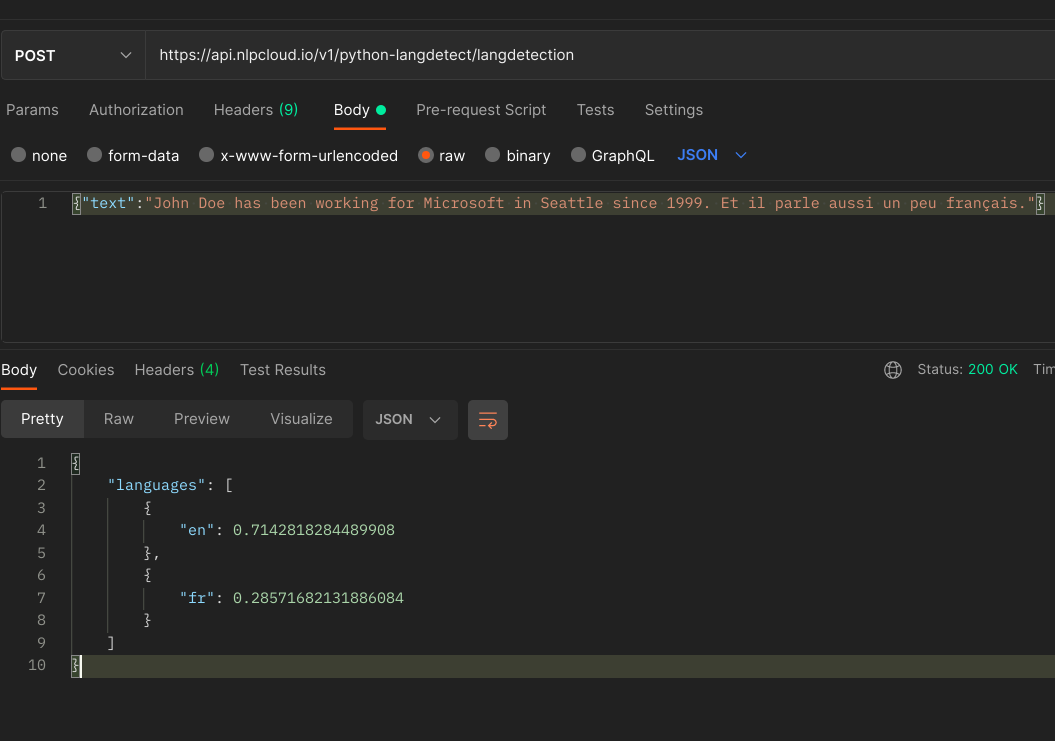
Put your JSON data in Body > raw. Note that if your text contains double quotes (") you will need to escape them (using \") in order for your JSON to be properly decoded. This is not needed when using a client library.
HTTP Request
POST https://api.nlpcloud.io/v1/python-langdetect/langdetection
POST Values
These values must be encoded as JSON.
| Key | Type | Description |
|---|---|---|
text |
string | The block of text containing one or more languages your want to detect. 25,000 tokens maximum. |
Output
This endpoint returns a JSON object called languages. Each object contains a detected language and its likelihood. The languages are sorted with the most likely first:
| Key | Type | Description |
|---|---|---|
languages |
array of objects. Each object has a string as key and float as value | The list of detected languages (in 2 characters ISO format) with their likelihood |
Noun Chunks
Input:
curl "https://api.nlpcloud.io/v1/<model_name>/noun-chunks" \
-H "Authorization: Token <token>" \
-H "Content-Type: application/json" \
-X POST \
-d '{"text":"John Doe has been working for the Microsoft company in Seattle since 1999."}'
# Not implemented yet.
# Not implemented yet.
// Not implemented yet.
// Not implemented yet.
// Not implemented yet.
Output (using en_core_web_lg for the example):
{
"noun_chunks":[
{
"text":"John Doe",
"root_text":"Doe",
"root_dep":"nsubj",
"root_head_text":"working"
},
{
"text":"the Microsoft company",
"root_text":"company",
"root_dep":"pobj",
"root_head_text":"for"
},
{
"text":"Seattle",
"root_text":"Seattle",
"root_dep":"pobj",
"root_head_text":"in"
}
]
}
This endpoint uses a spaCy model (it can be either a spaCy pre-trained model or your own spaCy custom model), or Megagon Lab's Ginza model for Japanese, to extract noun chunks from a piece of text, in many languages.
See the spaCy noun chunks documentation for more details.
If you are using Megagon Lab's Ginza model for Japanese, see the documentation here.
Here are all the spaCy models you can use in many languages (see the models section for more details):
- en_core_web_lg: spaCy large English
- ja_ginza_electra: Ginza Electra Japanese
- ja_core_news_lg: spaCy large Japanese
- fr_core_news_lg: spaCy large French
- zh_core_web_lg: spaCy large Chinese
- da_core_news_lg: spaCy large Danish
- nl_core_news_lg: spaCy large Dutch
- de_core_news_lg: spaCy large German
- el_core_news_lg: spaCy large Greek
- it_core_news_lg: spaCy large Italian
- lt_core_news_lg: spaCy large Lithuanian
- nb_core_news_lg: spaCy large Norwegian okmål
- pl_core_news_lg: spaCy large Polish
- pt_core_news_lg: spaCy large Portuguese
- ro_core_news_lg: spaCy large Romanian
- es_core_news_lg: spaCy large Spanish
It returns a list of noun chunks. Each noun chunk is an object made up of several elements. See below for the details.
HTTP Request
POST https://api.nlpcloud.io/v1/<model_name>/noun-chunks
POST Values
These values must be encoded as JSON.
| Parameter | Type | Description |
|---|---|---|
| text | string | The sentence containing the noun chunks to extract. 350 tokens maximum. |
Output
This endpoint returns a noun_chunks object containing an array of noun chunk objects.
Each noun chunk object contains the following:
| Key | Type | Description |
|---|---|---|
text |
string | The content of the extracted noun chunk |
root_text |
string | The original text of the word connecting the noun chunk to the rest of the parse |
root_dep |
string | Dependency relation connecting the root to its head |
root_head_text |
string | The text of the root token’s head |
Paraphrasing and Rewriting
Input:
curl "https://api.nlpcloud.io/v1/gpu/<model>/paraphrasing" \
-H "Authorization: Token <token>" \
-H "Content-Type: application/json" \
-X POST -d '{"text":"Language has historically been difficult for computers to ‘understand’. Sure, computers can collect, store, and read text inputs but they lack basic language context."}'
import nlpcloud
client = nlpcloud.Client("<model>", "<token>", True)
# Returns a json object.
client.paraphrasing("""Language has historically been difficult for computers to ‘understand’. Sure, computers can collect, store, and read text inputs but they lack basic language context.""")
require 'nlpcloud'
client = NLPCloud::Client.new('<model>','<token>', gpu: true)
# Returns a json object.
client.paraphrasing("Language has historically been difficult for computers to ‘understand’. Sure, computers can collect, store, and read text inputs but they lack basic language context.")
import (
"net/http"
"github.com/nlpcloud/nlpcloud-go"
)
func main() {
client := nlpcloud.NewClient(&http.Client{}, nlpcloud.ClientParams{Model:"<model_name>", Token:"<token>",
GPU:true, Lang:"", Async:false})
// Returns a Paraphrasing struct.
paraphrase, err := client.Paraphrasing(nlpcloud.ParaphrasingParams{
Text: `Language has historically been difficult for computers to ‘understand’. Sure, computers can collect, store, and read text inputs but they lack basic language context.`,
})
...
}
const NLPCloudClient = require('nlpcloud');
const client = new NLPCloudClient({model:'<model>',token:'<token>',gpu:true})
// Returns an Axios promise with the results.
// In case of success, results are contained in `response.data`.
// In case of failure, you can retrieve the status code in `err.response.status`
// and the error message in `err.response.data.detail`.
client.paraphrasing({text:`Language has historically been difficult for computers to ‘understand’. Sure, computers can collect, store, and read text inputs but they lack basic language context.`}).then(function (response) {
console.log(response.data);
})
.catch(function (err) {
console.error(err.response.status);
console.error(err.response.data.detail);
});
require 'vendor/autoload.php';
use NLPCloud\NLPCloud;
$client = new \NLPCloud\NLPCloud('<model>','<token>', True);
# Returns a json object.
echo json_encode($client->paraphrasing("Language has historically been difficult for computers to ‘understand’. Sure, computers can collect, store, and read text inputs but they lack basic language context."));
Output:
{
"paraphrased_text": "Language is difficult for computers to understand. Computers can read texts but they can’t interpret context."
}
This endpoint performs text paraphrasing and rewriting. The model rephrases your original text so the words are different but the meaning remains the same.
For paraphrasing in non-English languages, you can use our multilingual add-on. Note that Fine-tuned LLaMA 3 70B natively works in many non English languages without even using the multilingual add-on.
Pass your block of text, and the model will return a paraphrase.
If you want more control over the paraphrasing, you should use the text generation endpoint together with few shot learning. And for the best results, you should fine-tune your own model. You can also use your own custom model.
You can use the following models:
- finetuned-llama-3-70b: It natively understands the following languages: Albanian, Arabic, Armenian, Awadhi, Azerbaijani, Bashkir, Basque, Belarusian, Bengali, Bhojpuri, Bosnian, Brazilian Portuguese, Bulgarian, Cantonese (Yue), Catalan, Chhattisgarhi, Chinese, Croatian, Czech, Danish, Dogri, Dutch, English, Estonian, Faroese, Finnish, French, Galician, Georgian, German, Greek, Gujarati, Haryanvi, Hindi, Hungarian, Indonesian, Irish, Italian, Japanese, Javanese, Kannada, Kashmiri, Kazakh, Konkani, Korean, Kyrgyz, Latvian, Lithuanian, Macedonian, Maithili, Malay, Maltese, Mandarin, Mandarin Chinese, Marathi, Marwari, Min Nan, Moldovan, Mongolian, Montenegrin, Nepali, Norwegian, Oriya, Pashto, Persian (Farsi), Polish, Portuguese, Punjabi, Rajasthani, Romanian, Russian, Sanskrit, Santali, Serbian, Sindhi, Sinhala, Slovak, Slovene, Slovenian, Spanish, Swahili, Swedish, Tajik, Tamil, Tatar, Telugu, Thai, Turkish, Turkmen, Ukrainian, Urdu, Uzbek, Vietnamese, Welsh, and Wu.
HTTP Request
POST https://api.nlpcloud.io/v1/gpu/<model_name>/paraphrasing
POST Values
These values must be encoded as JSON.
| Key | Type | Description |
|---|---|---|
text |
string | The sentences you want to paraphrase. The maximum input text is 1 million tokens in asyncrhonous mode, and it is 256 tokens in synchronous mode. |
Output
This endpoint returns a JSON object containing the following elements:
| Key | Type | Description |
|---|---|---|
paraphrased_text |
string | The paraphrase of your text |
Question Answering
Input:
curl "https://api.nlpcloud.io/v1/<model_name>/question" \
-H "Authorization: Token <token>" \
-H "Content-Type: application/json" \
-X POST -d '{
"question":"When can plans be stopped?",
"context":"All NLP Cloud plans can be stopped anytime. You only pay for the time you used the service. In case of a downgrade, you will get a discount on your next invoice."
}'
import nlpcloud
client = nlpcloud.Client("<model_name>", "<token>")
# Returns a json object.
client.question("When can plans be stopped?",
context="""All NLP Cloud plans can be stopped anytime. You only pay for the time you used the service. In case of a downgrade, you will get a discount on your next invoice.""")
require 'nlpcloud'
client = NLPCloud::Client.new('<model_name>','<token>')
# Returns a json object.
client.question("When can plans be stopped?",
context: "All NLP Cloud plans can be stopped anytime. You only pay for the time you used the service. In case of a downgrade, you will get a discount on your next invoice.")
import (
"net/http"
"github.com/nlpcloud/nlpcloud-go"
)
func main() {
client := nlpcloud.NewClient(&http.Client{}, nlpcloud.ClientParams{Model:"<model_name>", Token:"<token>",
GPU:false, Lang:"", Async:false})
// Returns a Question struct.
answer, err := client.Question(nlpcloud.QuestionParams{
Question: "When can plans be stopped?",
Context: `All NLP Cloud plans can be stopped anytime. You only pay for the time you used the service. In case of a downgrade, you will get a discount on your next invoice.`,
})
...
}
const NLPCloudClient = require('nlpcloud');
const client = new NLPCloudClient({model:'<model_name>',token:'<token>'})
// Returns an Axios promise with the results.
// In case of success, results are contained in `response.data`.
// In case of failure, you can retrieve the status code in `err.response.status`
// and the error message in `err.response.data.detail`.
client.question({question:`When can plans be stopped?`,
context:`All NLP Cloud plans can be stopped anytime. You only pay for the time you used the service. In case of a downgrade, you will get a discount on your next invoice.`}).then(function (response) {
console.log(response.data);
})
.catch(function (err) {
console.error(err.response.status);
console.error(err.response.data.detail);
});
require 'vendor/autoload.php';
use NLPCloud\NLPCloud;
$client = new \NLPCloud\NLPCloud('<model_name>','<token>');
# Returns a json object.
echo json_encode($client->question("When can plans be stopped?",
"All NLP Cloud plans can be stopped anytime. You only pay for the time you used the service. In case of a downgrade, you will get a discount on your next invoice."));
Output:
{
"answer":"Anytime",
"score":0.9595934152603149,
"start":17,
"end":32
}
This endpoint answer questions about anything. As an option, you can give a context and ask a specific question about it.
For question answering in non-English languages, you can use our multilingual add-on. Note that Fine-tuned LLaMA 3 70B natively works quite well in many non English languages without even using the multilingual add-on.
For question answering on a large set of documents, you might want to read this article: Question Answering On Domain Knowledge With Semantic Search And Text Generation.
Here are the models you can use:
- finetuned-llama-3-70b: It natively understands the following languages: Albanian, Arabic, Armenian, Awadhi, Azerbaijani, Bashkir, Basque, Belarusian, Bengali, Bhojpuri, Bosnian, Brazilian Portuguese, Bulgarian, Cantonese (Yue), Catalan, Chhattisgarhi, Chinese, Croatian, Czech, Danish, Dogri, Dutch, English, Estonian, Faroese, Finnish, French, Galician, Georgian, German, Greek, Gujarati, Haryanvi, Hindi, Hungarian, Indonesian, Irish, Italian, Japanese, Javanese, Kannada, Kashmiri, Kazakh, Konkani, Korean, Kyrgyz, Latvian, Lithuanian, Macedonian, Maithili, Malay, Maltese, Mandarin, Mandarin Chinese, Marathi, Marwari, Min Nan, Moldovan, Mongolian, Montenegrin, Nepali, Norwegian, Oriya, Pashto, Persian (Farsi), Polish, Portuguese, Punjabi, Rajasthani, Romanian, Russian, Sanskrit, Santali, Serbian, Sindhi, Sinhala, Slovak, Slovene, Slovenian, Spanish, Swahili, Swedish, Tajik, Tamil, Tatar, Telugu, Thai, Turkish, Turkmen, Ukrainian, Urdu, Uzbek, Vietnamese, Welsh, and Wu.
- chatdolphin: It works best in English.
- dolphin-yi-34b: It works best in English.
- dolphin-mixtral-8x7b: It works best in English.
You can also use your own custom model.
Here is an example using Postman:
Put your JSON data in Body > raw. Note that if your text contains double quotes (") you will need to escape them (using \") in order for your JSON to be properly decoded. This is not needed when using a client library.
HTTP Request
POST https://api.nlpcloud.io/v1/<model_name>/question
POST Values
These values must be encoded as JSON.
| Key | Type | Description |
|---|---|---|
question |
string | The question you want to ask |
context |
string | The block of text that the model will use in order to find an answer to your question. Maximum 4096 tokens for Fine-tuned LLaMA 3 70B. 8192 tokens for the other models. Optional. |
Output
This endpoint returns a JSON object containing the following elements:
| Key | Type | Description |
|---|---|---|
answer |
string | The answer to your question |
score |
float | The accuracy of the answer. It goes from 0 to 1. The higher the score, the more accurate the answer is. Not meaningful if you're using a generative model. |
start |
integer | Position of the starting character of the response in your context. Not meaningful if you're using a generative model. |
end |
integer | Position of the ending character of the response in your context. Not meaningful if you're using a generative model. |
Sentence Dependencies
Input:
curl "https://api.nlpcloud.io/v1/<model_name>/sentence-dependencies" \
-H "Authorization: Token <token>" \
-H "Content-Type: application/json" \
-X POST \
-d '{"text":"John Doe is a Go Developer at Google. Before that, he worked at Microsoft."}'
import nlpcloud
client = nlpcloud.Client("<model_name>", "<token>")
# Returns json object.
client.sentence_dependencies("John Doe is a Go Developer at Google. Before that, he worked at Microsoft.")
require 'nlpcloud'
client = NLPCloud::Client.new('<model_name>','<token>')
# Returns json object.
client.sentence_dependencies("John Doe is a Go Developer at Google. Before that, he worked at Microsoft.")
import (
"net/http"
"github.com/nlpcloud/nlpcloud-go"
)
func main() {
client := nlpcloud.NewClient(&http.Client{}, nlpcloud.ClientParams{Model:"<model_name>", Token:"<token>",
GPU:false, Lang:"", Async:false})
// Returns a SentenceDependencies struct.
sentenceDependencies, err := client.SentenceDependencies(nlpcloud.SentenceDependenciesParams{
Text: "John Doe is a Go Developer at Google. Before that, he worked at Microsoft.",
})
...
}
const NLPCloudClient = require('nlpcloud');
const client = new NLPCloudClient({model:'<model_name>',token:'<token>'})
// Returns an Axios promise with the results.
// In case of success, results are contained in `response.data`.
// In case of failure, you can retrieve the status code in `err.response.status`
// and the error message in `err.response.data.detail`.
client.sentenceDependencies({text:'John Doe is a Go Developer at Google. Before that, he worked at Microsoft.'}).then(function (response) {
console.log(response.data);
})
.catch(function (err) {
console.error(err.response.status);
console.error(err.response.data.detail);
});
require 'vendor/autoload.php';
use NLPCloud\NLPCloud;
$client = new \NLPCloud\NLPCloud('<model_name>','<token>');
# Returns a json object.
echo json_encode($client->sentenceDependencies("John Doe is a Go Developer at Google. Before that, he worked at Microsoft."));
Output (using en_core_web_lg for the example):
{
"sentence_dependencies": [
{
"sentence": "John Doe is a Go Developer at Google.",
"dependencies": {
"words": [
{
"text": "John",
"tag": "NNP"
},
{
"text": "Doe",
"tag": "NNP"
},
{
"text": "is",
"tag": "VBZ"
},
{
"text": "a",
"tag": "DT"
},
{
"text": "Go",
"tag": "NNP"
},
{
"text": "Developer",
"tag": "NN"
},
{
"text": "at",
"tag": "IN"
},
{
"text": "Google",
"tag": "NNP"
},
{
"text": ".",
"tag": "."
}
],
"arcs": [
{
"start": 0,
"end": 1,
"label": "compound",
"text": "John",
"dir": "left"
},
{
"start": 1,
"end": 2,
"label": "nsubj",
"text": "Doe",
"dir": "left"
},
{
"start": 3,
"end": 5,
"label": "det",
"text": "a",
"dir": "left"
},
{
"start": 4,
"end": 5,
"label": "compound",
"text": "Go",
"dir": "left"
},
{
"start": 2,
"end": 5,
"label": "attr",
"text": "Developer",
"dir": "right"
},
{
"start": 5,
"end": 6,
"label": "prep",
"text": "at",
"dir": "right"
},
{
"start": 6,
"end": 7,
"label": "pobj",
"text": "Google",
"dir": "right"
},
{
"start": 2,
"end": 8,
"label": "punct",
"text": ".",
"dir": "right"
}
]
}
},
{
"sentence": "Before that, he worked at Microsoft.",
"dependencies": {
"words": [
{
"text": "Before",
"tag": "IN"
},
{
"text": "that",
"tag": "DT"
},
{
"text": ",",
"tag": ","
},
{
"text": "he",
"tag": "PRP"
},
{
"text": "worked",
"tag": "VBD"
},
{
"text": "at",
"tag": "IN"
},
{
"text": "Microsoft",
"tag": "NNP"
},
{
"text": ".",
"tag": "."
}
],
"arcs": [
{
"start": 9,
"end": 13,
"label": "prep",
"text": "Before",
"dir": "left"
},
{
"start": 9,
"end": 10,
"label": "pobj",
"text": "that",
"dir": "right"
},
{
"start": 11,
"end": 13,
"label": "punct",
"text": ",",
"dir": "left"
},
{
"start": 12,
"end": 13,
"label": "nsubj",
"text": "he",
"dir": "left"
},
{
"start": 13,
"end": 14,
"label": "prep",
"text": "at",
"dir": "right"
},
{
"start": 14,
"end": 15,
"label": "pobj",
"text": "Microsoft",
"dir": "right"
},
{
"start": 13,
"end": 16,
"label": "punct",
"text": ".",
"dir": "right"
}
]
}
}
]
}
This endpoint uses a spaCy model (it can be either a spaCy pre-trained model or your own spaCy custom model), or Megagon Lab's Ginza model for Japanese, to perform Part-of-Speech (POS) tagging , in many languages and returns dependencies (arcs) extracted from the passed in text, for several sentences.
See the spaCy dependency parsing documentation for more details.
If you are using Megagon Lab's Ginza model for Japanese, see the documentation here.
Here are all the spaCy models you can use in multiple languages (see the models section for more details) :
- en_core_web_lg: spaCy large English
- ja_ginza_electra: Ginza Electra Japanese
- ja_core_news_lg: spaCy large Japanese
- fr_core_news_lg: spaCy large French
- zh_core_web_lg: spaCy large Chinese
- da_core_news_lg: spaCy large Danish
- nl_core_news_lg: spaCy large Dutch
- de_core_news_lg: spaCy large German
- el_core_news_lg: spaCy large Greek
- it_core_news_lg: spaCy large Italian
- lt_core_news_lg: spaCy large Lithuanian
- nb_core_news_lg: spaCy large Norwegian okmål
- pl_core_news_lg: spaCy large Polish
- pt_core_news_lg: spaCy large Portuguese
- ro_core_news_lg: spaCy large Romanian
- es_core_news_lg: spaCy large Spanish
Each spaCy and Ginza pre-trained model has a list of supported built-in part-of-speech tags and dependency labels. For example, the list of tags and dependency labels for the en_core_web_lg model can be found here:
- Tags: $, '', ,, -LRB-, -RRB-, ., :, ADD, AFX, CC, CD, DT, EX, FW, HYPH, IN, JJ, JJR, JJS, LS, MD, NFP, NN, NNP, NNPS, NNS, PDT, POS, PRP, PRP$, RB, RBR, RBS, RP, SYM, TO, UH, VB, VBD, VBG, VBN, VBP, VBZ, WDT, WP, WP$, WRB, XX, ``
- Dependency labels: ROOT, acl, acomp, advcl, advmod, agent, amod, appos, attr, aux, auxpass, case, cc, ccomp, compound, conj, csubj, csubjpass, dative, dep, det, dobj, expl, intj, mark, meta, neg, nmod, npadvmod, nsubj, nsubjpass, nummod, oprd, parataxis, pcomp, pobj, poss, preconj, predet, prep, prt, punct, quantmod, relcl, xcomp
For more details about what these abbreviations mean, see spaCy's glossary.
HTTP Request
POST https://api.nlpcloud.io/v1/<model_name>/sentence-dependencies
POST Values
These values must be encoded as JSON.
| Parameter | Type | Description |
|---|---|---|
| text | string | The sentences containing parts of speech to extract. 350 tokens maximum. |
Output
This endpoint returns a sentence_dependencies object containing an array of sentence dependencies objects.
Each sentence dependency object contains the following:
| Key | Type | Description |
|---|---|---|
sentence |
string | The sentence being analyzed |
dependencies |
object | An object containing the words and arcs |
words contains an array of the following elements:
| Key | Type | Description |
|---|---|---|
text |
string | The content of the word |
tag |
string | The part of speech tag for the word (https://spacy.io/api/annotation#pos-tagging) |
arcs contains an array of the following elements:
| Key | Type | Description |
|---|---|---|
text |
string | The content of the word |
label |
string | The syntactic dependency connecting child to head (https://spacy.io/api/annotation#pos-tagging) |
start |
integer | Position of the word if direction of the arc is left. Position of the head if direction of the arc is right. |
end |
integer | Position of the head if direction of the arc is left. Position of the word if direction of the arc is right. |
dir |
string | Direction of the dependency arc (left or right) |
Sentiment Analysis
Input:
curl "https://api.nlpcloud.io/v1/<model_name>/sentiment" \
-H "Authorization: Token <token>" \
-H "Content-Type: application/json" \
-X POST -d '{"text":"NLP Cloud proposes an amazing service!"}'
import nlpcloud
client = nlpcloud.Client("<model_name>", "<token>")
# Returns a json object.
client.sentiment("NLP Cloud proposes an amazing service!")
require 'nlpcloud'
client = NLPCloud::Client.new('<model_name>','<token>')
# Returns a json object.
client.sentiment("NLP Cloud proposes an amazing service!")
import (
"net/http"
"github.com/nlpcloud/nlpcloud-go"
)
func main() {
client := nlpcloud.NewClient(&http.Client{}, nlpcloud.ClientParams{Model:"<model_name>", Token:"<token>",
GPU:false, Lang:"", Async:false})
// Returns a Sentiment struct.
sentiment, err := client.Sentiment(nlpcloud.SentimentParams{
Text: "NLP Cloud proposes an amazing service!",
})
...
}
const NLPCloudClient = require('nlpcloud');
const client = new NLPCloudClient({model:'<model_name>',token:'<token>'})
// Returns an Axios promise with the results.
// In case of success, results are contained in `response.data`.
// In case of failure, you can retrieve the status code in `err.response.status`
// and the error message in `err.response.data.detail`.
client.sentiment({text:'NLP Cloud proposes an amazing service!'}).then(function (response) {
console.log(response.data);
})
.catch(function (err) {
console.error(err.response.status);
console.error(err.response.data.detail);
});
require 'vendor/autoload.php';
use NLPCloud\NLPCloud;
$client = new \NLPCloud\NLPCloud('<model_name>','<token>');
# Returns a json object.
echo json_encode($client->sentiment("NLP Cloud proposes an amazing service!"));
Output (using distilbert-base-uncased-finetuned-sst-2-english for the example):
{
"scored_labels":[
{
"label":"POSITIVE",
"score":0.9996881484985352
}
]
}
This endpoint performs sentiment and emotion analysis.
For sentiment and emotions analysis in non-English languages, you can use our multilingual add-on.
Here are the 6 transformer-based models you can use:
- distilbert-base-uncased-finetuned-sst-2-english: for sentiment analysis (whether a text is positive or negative) in English
- distilbert-base-uncased-emotion: for emotion analysis (detect sadness, joy, love, anger, fear, and surprise) in English
you can also use your own custom model.
Pass your text and let the model apply sentiment and emotion labels, with a score. The higher the score, the more accurate the label is.
Here is an example using Postman:
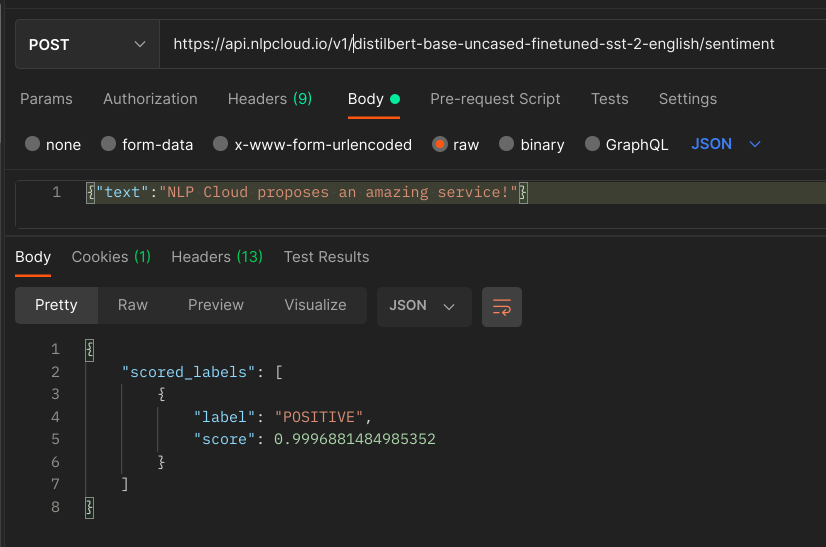
Put your JSON data in Body > raw. Note that if your text contains double quotes (") you will need to escape them (using \") in order for your JSON to be properly decoded. This is not needed when using a client library.
HTTP Request
POST https://api.nlpcloud.io/v1/<model_name>/sentiment
POST Values
These values must be encoded as JSON.
| Key | Type | Description |
|---|---|---|
text |
string | The block of text you want to analyze. 512 tokens maximum. |
Output
This endpoint returns a JSON object containing a list of labels called scored_labels.
| Key | Type | Description |
|---|---|---|
scored_labels |
array of objects | The returned scored labels. It can be one or two scored labels. |
Each score label is an object made up of the following elements:
| Key | Type | Description |
|---|---|---|
label |
string | The sentiment or emotion detected (POSITIVE, NEGATIVE, sadness, joy, love, anger, fear, surprise) |
score |
float | The score applied to the label. It goes from 0 to 1. The higher the score, the more important the sentiment or emotion is. |
Semantic Search
Input:
curl "https://api.nlpcloud.io/v1/gpu/custom-model/<model_id>/semantic-search" \
-H "Authorization: Token <token>" \
-H "Content-Type: application/json" \
-X POST \
-d '{"text":"How long is the warranty on the HP Color LaserJet Pro?"}'
import nlpcloud
client = nlpcloud.Client("custom-model/<model_id>", "<token>", gpu=True)
# Returns json object.
client.semantic_search("How long is the warranty on the HP Color LaserJet Pro?")
require 'nlpcloud'
client = NLPCloud::Client.new('custom-model/<model_id>','<token>', gpu: true)
# Returns a json object.
client.semantic_search("How long is the warranty on the HP Color LaserJet Pro?")
import (
"net/http"
"github.com/nlpcloud/nlpcloud-go"
)
func main() {
client := nlpcloud.NewClient(&http.Client{}, nlpcloud.ClientParams{Model:"custom_model/<model_id>", Token:"<token>",
GPU:true, Lang:"", Async:false})
// Returns SemanticSearch struct.
semanticSearch, err := client.SemanticSearch(nlpcloud.SemanticSearchParams{
Text: "How long is the warranty on the HP Color LaserJet Pro?",
})
...
}
const NLPCloudClient = require('nlpcloud');
const client = new NLPCloudClient({model:'custom-model/<model_id>',token:'<token>',gpu:true})
// Returns an Axios promise with the results.
// In case of success, results are contained in `response.data`.
// In case of failure, you can retrieve the status code in `err.response.status`
// and the error message in `err.response.data.detail`.
client.semanticSearch({text:'How long is the warranty on the HP Color LaserJet Pro?'}).then(function (response) {
console.log(response.data);
})
.catch(function (err) {
console.error(err.response.status);
console.error(err.response.data.detail);
});
require 'vendor/autoload.php';
use NLPCloud\NLPCloud;
$client = new \NLPCloud\NLPCloud('custom-model/<model_id>','<token>', True);
# Returns a json object.
echo json_encode($client->semanticSearch("How long is the warranty on the HP Color LaserJet Pro?"));
Output:
{
"search_results": [
{
"score": 0.99,
"text": "Every HP LaserJet comes with a one-year HP commercial warranty (or HP Limited Warranty)."
},
{
"score": 0.74,
"text": "All consumer PCs and printers come with a standard one-year warranty. Care packs provide an enhanced level of support and/or an extended period of coverage for your HP hardware. All commercial PCs and printers come with either a one-year or three-year warranty."
},
{
"score": 0.68,
"text": "In-warranty plan · Available in 2-, 3-, or 4-year extension plans · Includes remote problem diagnosis support and Next Business Day Exchange Service."
},
]
}
This endpoint uses a Sentence Transformers model, to search your own data, in more than 50 languages (see the full list here).
Not sure what semantic search is about exactly? You can read this good article about it.
Simply upload a dataset containing your data, in your dashboard. We will then automatically select the best Sentence Transformers model for you and fine-tune it with your data. The automatic choice of the model will depend on factors like the languages contained in your dataset, and the length of your examples. If you already know which model you need, you can also let us know in advance and we will make sure that it is the model that will be used under the hood.
Your dataset should simply be a 1-column CSV file. Each row can contain up to 512 tokens (roughly equivalent to 400 words), and in order to maximise accuracy, it is recommended to stay below 128 tokens (roughly equivalent to 100 words). You can include as-many examples as you want. For example, let's say you are a HP printers reseller, and you want to enable semantic search on your shop website. You can create a CSV that will look like this.
| HP® LaserJets have unmatched printing speed, performance and reliability that you can trust. Enjoy Low Prices and Free Shipping when you buy now online. |
| Every HP LaserJet comes with a one-year HP commercial warranty (or HP Limited Warranty). |
| HP LaserJet ; Lowest cost per page on mono laser printing. · $319.99 ; Wireless options available. · $109.00 ; Essential management features. · $209.00. |
Once your model is ready, you will receive an email containing a private model ID, and explaining how to use it.
Then, you can simply make a request like you would do on Google. It can either be mere keywords or a proper question. For example, based on the above dataset, you can ask something like this: "How long is the warranty on the HP Color LaserJet Pro?". Or like this: "period warranty HP Color LaserJet Pro". And the model will return: "Every HP LaserJet comes with a one-year HP commercial warranty (or HP Limited Warranty).".
This API endpoint is compatible with our multilingual addon.
In order to create a chatbot that will correctly answer questions on your own knowledge, you will need to mix both semantic search and generative AI. Please read this article: Question Answering On Domain Knowledge With Semantic Search And Generative AI.
HTTP Request
POST https://api.nlpcloud.io/v1/gpu/custom-model/<model_id>/semantic-search
POST Values
These values must be encoded as JSON.
| Parameter | Type | Description |
|---|---|---|
| text | string | Your search query applied to your own data. 512 tokens maximum. |
| num_results | int | Number of results returned. Optional. 1 minimum and 1000 maximum. Defaults to 5. |
Output
This endpoint returns search_results, which is an array of results. Each result contains a text result, extracted from your own data, together with an accuracy score:
| Key | Type | Description |
|---|---|---|
text |
string | A result for your search query, extracted from your own data. |
score |
float | Accuracy of the result. Between 0 to 1. 0 means not likely, and 1 means very likely. |
Semantic Similarity
Input:
curl "https://api.nlpcloud.io/v1/paraphrase-multilingual-mpnet-base-v2/semantic-similarity" \
-H "Authorization: Token <token>" \
-H "Content-Type: application/json" \
-X POST \
-d '{"sentences":["John Does works for Google and he hates it.","John Does works for NLP Cloud and he love it."]}'
import nlpcloud
client = nlpcloud.Client("<model_name>", "<token>")
# Returns json object.
client.semantic_similarity(["John Does works for Google and he hates it.","John Does works for NLP Cloud and he love it."])
require 'nlpcloud'
client = NLPCloud::Client.new('<model_name>','<token>')
# Returns a json object.
client.semantic_similarity(["John Does works for Google and he hates it.","John Does works for NLP Cloud and he love it."])
import (
"net/http"
"github.com/nlpcloud/nlpcloud-go"
)
func main() {
client := nlpcloud.NewClient(&http.Client{}, nlpcloud.ClientParams{Model:"<model_name>", Token:"<token>",
GPU:false, Lang:"", Async:false})
// Returns SemanticSimilarity struct.
semanticSimilarity, err := client.SemanticSimilarity(nlpcloud.SemanticSimilarityParams{
Sentences: [2]string{"John Does works for Google and he hates it.","John Does works for NLP Cloud and he love it."},
})
...
}
const NLPCloudClient = require('nlpcloud');
const client = new NLPCloudClient({model:'<model_name>',token:'<token>'})
// Returns an Axios promise with the results.
// In case of success, results are contained in `response.data`.
// In case of failure, you can retrieve the status code in `err.response.status`
// and the error message in `err.response.data.detail`.
client.semanticSimilarity({sentences:['<Block of text 1>', '<Block of text 2>']}).then(function (response) {
console.log(response.data);
})
.catch(function (err) {
console.error(err.response.status);
console.error(err.response.data.detail);
});
require 'vendor/autoload.php';
use NLPCloud\NLPCloud;
$client = new \NLPCloud\NLPCloud('<model_name>','<token>');
# Returns a json object.
echo json_encode($client->semanticSimilarity(array("<Block of text 1>", "<Block of text 2>")));
Output:
{
"score": 0.31693190336227417
}
This endpoint uses the Paraphrase Multilingual MPNet Base V2 model, based on Sentence Transformers, to calculate the semantic similarity between 2 pieces of text, in more than 50 languages (see the full list here).
It returns a score. The higher the score, the more likely the 2 pieces of text have the same meaning.
HTTP Request
POST https://api.nlpcloud.io/v1/paraphrase-multilingual-mpnet-base-v2/semantic-similarity
POST Values
These values must be encoded as JSON.
| Parameter | Type | Description |
|---|---|---|
| sentences | array of strings | The pieces of text you want to analyze. The array should contain exactly 2 elements. Each element should contain 128 tokens maximum. |
Output
This endpoint returns a score that indicates whether the input pieces of text have the same meaning or not:
| Key | Type | Description |
|---|---|---|
score |
float | The score that indicates whether the input texts have the same meaning or not. It goes from 0 to 1. The higher the score, the more likely the 2 pieces of text have the same meaning. |
Speech Synthesis
Input:
curl "https://api.nlpcloud.io/v1/gpu/speech-t5/speech-synthesis" \
-H "Authorization: Token <token>" \
-H "Content-Type: application/json" \
-X POST -d '{"text":"This report summarizes a discussion between John and his doctor."}'
import nlpcloud
client = nlpcloud.Client("speech-t5", "<token>", True)
# Returns a json object.
client.speech_synthesis("""This report summarizes a discussion between John and his doctor.""")
require 'nlpcloud'
client = NLPCloud::Client.new('speech-t5','<token>', gpu: true)
# Returns a json object.
client.speech_synthesis("This report summarizes a discussion between John and his doctor.")
import (
"net/http"
"github.com/nlpcloud/nlpcloud-go"
)
func main() {
client := nlpcloud.NewClient(&http.Client{}, nlpcloud.ClientParams{Model:"speech-t5", Token:"<token>",
GPU:true, Lang:"", Async:false})
// Returns an ImageGeneration struct.
image, err := client.speechSynthesis(nlpcloud.ImageGenerationParams{
Text: "This report summarizes a discussion between John and his doctor.",
})
...
}
const NLPCloudClient = require('nlpcloud');
const client = new NLPCloudClient({model:'speech-t5',token:'<token>',gpu:true})
// Returns an Axios promise with the results.
// In case of success, results are contained in `response.data`.
// In case of failure, you can retrieve the status code in `err.response.status`
// and the error message in `err.response.data.detail`.
client.speechSynthesis({text:'This report summarizes a discussion between John and his doctor.'}).then(function (response) {
console.log(response.data);
})
.catch(function (err) {
console.error(err.response.status);
console.error(err.response.data.detail);
});
require 'vendor/autoload.php';
use NLPCloud\NLPCloud;
$client = new \NLPCloud\NLPCloud('speech-t5','<token>',True);
# Returns a json object.
echo json_encode($client->speechSynthesis("This report summarizes a discussion between John and his doctor."));
Output:
{
"url": "https://d2pgcgj5ldlmy6.cloudfront.net/d718942adee743f698ca8b5f5ff848we.wav"
}
This endpoint uses Microsoft's Speech T5 to generate a .wav audio file out of text. Once generated, the audio file is automatically stored on a Cloudfront CDN and a URL to the audio file is returned. You can then use the URL to download the audio or embed it in your application.
This model works in English only, and you can choose whether the speaker is a man or a woman.
Here is the model you can use:
- speech-t5 for speech synthesis in English.
HTTP Request
POST https://api.nlpcloud.io/v1/gpu/speech-t5/speech-synthesis
POST Values
These values must be encoded as JSON.
| Key | Type | Description |
|---|---|---|
text |
string | Your text instruction for audio generation. 512 tokens maximum. |
voice |
string | The type of speaker you would like to use. Possible values are "man" and "woman". Defaults to "woman". Optional. |
Output
This endpoint returns a JSON object containing the following elements:
| Key | Type | Description |
|---|---|---|
url |
string | The URL to the generated audio file, hosted on a Cloudfront CDN |
Summarization
Input:
curl "https://api.nlpcloud.io/v1/<model_name>/summarization" \
-H "Authorization: Token <token>" \
-H "Content-Type: application/json" \
-X POST -d '{"text":"One month after the United States began what has become a
troubled rollout of a national COVID vaccination campaign, the effort is finally
gathering real steam. Close to a million doses -- over 951,000, to be more exact --
made their way into the arms of Americans in the past 24 hours, the U.S. Centers
for Disease Control and Prevention reported Wednesday. That s the largest number
of shots given in one day since the rollout began and a big jump from the
previous day, when just under 340,000 doses were given, CBS News reported.
That number is likely to jump quickly after the federal government on Tuesday
gave states the OK to vaccinate anyone over 65 and said it would release all
the doses of vaccine it has available for distribution. Meanwhile, a number
of states have now opened mass vaccination sites in an effort to get larger
numbers of people inoculated, CBS News reported."}'
import nlpcloud
client = nlpcloud.Client("<model_name>", "<token>")
# Returns a json object.
client.summarization("""One month after the United States began what has become a
troubled rollout of a national COVID vaccination campaign, the effort is finally
gathering real steam. Close to a million doses -- over 951,000, to be more exact --
made their way into the arms of Americans in the past 24 hours, the U.S. Centers
for Disease Control and Prevention reported Wednesday. That s the largest number
of shots given in one day since the rollout began and a big jump from the
previous day, when just under 340,000 doses were given, CBS News reported.
That number is likely to jump quickly after the federal government on Tuesday
gave states the OK to vaccinate anyone over 65 and said it would release all
the doses of vaccine it has available for distribution. Meanwhile, a number
of states have now opened mass vaccination sites in an effort to get larger
numbers of people inoculated, CBS News reported.""")
require 'nlpcloud'
client = NLPCloud::Client.new('<model_name>','<token>')
# Returns a json object.
client.summarization("One month after the United States began what has become a
troubled rollout of a national COVID vaccination campaign, the effort is finally
gathering real steam. Close to a million doses -- over 951,000, to be more exact --
made their way into the arms of Americans in the past 24 hours, the U.S. Centers
for Disease Control and Prevention reported Wednesday. That s the largest number
of shots given in one day since the rollout began and a big jump from the
previous day, when just under 340,000 doses were given, CBS News reported.
That number is likely to jump quickly after the federal government on Tuesday
gave states the OK to vaccinate anyone over 65 and said it would release all
the doses of vaccine it has available for distribution. Meanwhile, a number
of states have now opened mass vaccination sites in an effort to get larger
numbers of people inoculated, CBS News reported.")
import (
"net/http"
"github.com/nlpcloud/nlpcloud-go"
)
func main() {
client := nlpcloud.NewClient(&http.Client{}, nlpcloud.ClientParams{Model:"<model_name>", Token:"<token>",
GPU:false, Lang:"", Async:false})
// Returns a Summarization struct.
summary, err := client.Summarization(nlpcloud.SummarizationParams{
Text: `One month after the United States began what has become a
troubled rollout of a national COVID vaccination campaign, the effort is finally
gathering real steam. Close to a million doses -- over 951,000, to be more exact --
made their way into the arms of Americans in the past 24 hours, the U.S. Centers
for Disease Control and Prevention reported Wednesday. That s the largest number
of shots given in one day since the rollout began and a big jump from the
previous day, when just under 340,000 doses were given, CBS News reported.
That number is likely to jump quickly after the federal government on Tuesday
gave states the OK to vaccinate anyone over 65 and said it would release all
the doses of vaccine it has available for distribution. Meanwhile, a number
of states have now opened mass vaccination sites in an effort to get larger
numbers of people inoculated, CBS News reported.`,
})
...
}
const NLPCloudClient = require('nlpcloud');
const client = new NLPCloudClient({model:'<model_name>',token:'<token>'})
// Returns an Axios promise with the results.
// In case of success, results are contained in `response.data`.
// In case of failure, you can retrieve the status code in `err.response.status`
// and the error message in `err.response.data.detail`.
client.summarization({text:`One month after the United States began what has become a
troubled rollout of a national COVID vaccination campaign, the effort is finally
gathering real steam. Close to a million doses -- over 951,000, to be more exact --
made their way into the arms of Americans in the past 24 hours, the U.S. Centers
for Disease Control and Prevention reported Wednesday. That s the largest number
of shots given in one day since the rollout began and a big jump from the
previous day, when just under 340,000 doses were given, CBS News reported.
That number is likely to jump quickly after the federal government on Tuesday
gave states the OK to vaccinate anyone over 65 and said it would release all
the doses of vaccine it has available for distribution. Meanwhile, a number
of states have now opened mass vaccination sites in an effort to get larger
numbers of people inoculated, CBS News reported.`}).then(function (response) {
console.log(response.data);
})
.catch(function (err) {
console.error(err.response.status);
console.error(err.response.data.detail);
});
require 'vendor/autoload.php';
use NLPCloud\NLPCloud;
$client = new \NLPCloud\NLPCloud('<model_name>','<token>');
# Returns a json object.
echo json_encode($client->summarization("One month after the United States began what has become a
troubled rollout of a national COVID vaccination campaign, the effort is finally
gathering real steam. Close to a million doses -- over 951,000, to be more exact --
made their way into the arms of Americans in the past 24 hours, the U.S. Centers
for Disease Control and Prevention reported Wednesday. That s the largest number
of shots given in one day since the rollout began and a big jump from the
previous day, when just under 340,000 doses were given, CBS News reported.
That number is likely to jump quickly after the federal government on Tuesday
gave states the OK to vaccinate anyone over 65 and said it would release all
the doses of vaccine it has available for distribution. Meanwhile, a number
of states have now opened mass vaccination sites in an effort to get larger
numbers of people inoculated, CBS News reported."));
Output (using bart-large-cnn for the example):
{
"summary_text": "Over 951,000 doses were given in the past 24 hours.
That's the largest number of shots given in one day since the rollout began.
That number is likely to jump quickly after the federal government
gave states the OK to vaccinate anyone over 65. A number of states have
now opened mass vaccination sites."
}
This endpoint performs text summarization in many languages. These are "abstractive" summarizations, which means that some sentences are directly taken from the input text, but also that new sentences might be generated.
For summarization in non-English languages, you can use our multilingual add-on. Note that Fine-tuned LLaMA 3 70B works in many non English languages without even using the multilingual add-on.
Pass your block of text, and the model will return a summary.
Here are the models you can use:
- bart-large-cnn for text summarization in English
- t5-base-en-generate-headline for headline generation in English
- finetuned-llama-3-70b: It natively understands the following languages: Albanian, Arabic, Armenian, Awadhi, Azerbaijani, Bashkir, Basque, Belarusian, Bengali, Bhojpuri, Bosnian, Brazilian Portuguese, Bulgarian, Cantonese (Yue), Catalan, Chhattisgarhi, Chinese, Croatian, Czech, Danish, Dogri, Dutch, English, Estonian, Faroese, Finnish, French, Galician, Georgian, German, Greek, Gujarati, Haryanvi, Hindi, Hungarian, Indonesian, Irish, Italian, Japanese, Javanese, Kannada, Kashmiri, Kazakh, Konkani, Korean, Kyrgyz, Latvian, Lithuanian, Macedonian, Maithili, Malay, Maltese, Mandarin, Mandarin Chinese, Marathi, Marwari, Min Nan, Moldovan, Mongolian, Montenegrin, Nepali, Norwegian, Oriya, Pashto, Persian (Farsi), Polish, Portuguese, Punjabi, Rajasthani, Romanian, Russian, Sanskrit, Santali, Serbian, Sindhi, Sinhala, Slovak, Slovene, Slovenian, Spanish, Swahili, Swedish, Tajik, Tamil, Tatar, Telugu, Thai, Turkish, Turkmen, Ukrainian, Urdu, Uzbek, Vietnamese, Welsh, and Wu.
- chatdolphin: It works best in English.
- dolphin-yi-34b: It works best in English.
- dolphin-mixtral-8x7b: It works best in English.
You can also use your own custom model.
Here is an example using Postman:
Put your JSON data in Body > raw. Note that if your text contains double quotes (") you will need to escape them (using \") in order for your JSON to be properly decoded. This is not needed when using a client library.
HTTP Request
POST https://api.nlpcloud.io/v1/<model_name>/summarization
POST Values
These values must be encoded as JSON.
| Key | Type | Description |
|---|---|---|
text |
string | The block of text that you want to summarize. In synchronous mode, it should not exceed 1024 tokens for Bart Large CNN, 4096 tokens for Fine-tuned LLaMA 3 70B and 8192 tokens maximum for the other models. In asynchronous mode it should not exceed 1 million tokens. |
size |
string | Determines the size of the summary. Possible values are "small" and "large". Defaults to "small". Not compatible with T5 Base. Optional. |
Output
This endpoint returns a JSON object containing the following elements:
| Key | Type | Description |
|---|---|---|
summary_text |
string | The summary of your text |
Tokens
Input:
curl "https://api.nlpcloud.io/v1/<model_name>/tokens" \
-H "Authorization: Token <token>" \
-H "Content-Type: application/json" \
-X POST \
-d '{"text":"John is a Go Developer at Google."}'
import nlpcloud
client = nlpcloud.Client("<model_name>", "<token>")
# Returns json object.
client.tokens("John is a Go Developer at Google.")
require 'nlpcloud'
client = NLPCloud::Client.new('<model_name>','<token>')
# Returns json object.
client.tokens("John is a Go Developer at Google.")
import (
"net/http"
"github.com/nlpcloud/nlpcloud-go"
)
func main() {
client := nlpcloud.NewClient(&http.Client{}, nlpcloud.ClientParams{Model:"<model_name>", Token:"<token>",
GPU:false, Lang:"", Async:false})
// Returns a Tokens struct.
tokens, err := client.Tokens(nlpcloud.TokensParams{
Text: "John Doe is a Go Developer at Google",
})
...
}
const NLPCloudClient = require('nlpcloud');
const client = new NLPCloudClient({model:'<model_name>',token:'<token>'})
// Returns an Axios promise with the results.
// In case of success, results are contained in `response.data`.
// In case of failure, you can retrieve the status code in `err.response.status`
// and the error message in `err.response.data.detail`.
client.tokens({text:'John is a Go Developer at Google.'}).then(function (response) {
console.log(response.data);
})
.catch(function (err) {
console.error(err.response.status);
console.error(err.response.data.detail);
});
require 'vendor/autoload.php';
use NLPCloud\NLPCloud;
$client = new \NLPCloud\NLPCloud('<model_name>','<token>');
# Returns a json object.
echo json_encode($client->tokens("John is a Go Developer at Google."));
Output (using en_core_web_lg for the example):
{
"tokens": [
{
"start": 0,
"end": 4,
"index": 1,
"text": "John",
"lemma": "John",
"ws_after": true
},
{
"start": 5,
"end": 7,
"index": 2,
"text": "is",
"lemma": "be",
"ws_after": true
},
{
"start": 8,
"end": 9,
"index": 3,
"text": "a",
"lemma": "a",
"ws_after": true
},
{
"start": 10,
"end": 12,
"index": 4,
"text": "Go",
"lemma": "Go",
"ws_after": true
},
{
"start": 13,
"end": 22,
"index": 5,
"text": "Developer",
"lemma": "developer",
"ws_after": true
},
{
"start": 23,
"end": 25,
"index": 6,
"text": "at",
"lemma": "at",
"ws_after": true
},
{
"start": 26,
"end": 32,
"index": 7,
"text": "Google",
"lemma": "Google",
"ws_after": false
},
{
"start": 32,
"end": 33,
"index": 8,
"text": ".",
"lemma": ".",
"ws_after": false
}
]
}
This endpoint uses a spaCy model (it can be either a spaCy pre-trained model or your own spaCy custom model), or Megagon Lab's Ginza model for Japanese, to tokenize and lemmatize a passed in text, in many languages.
See the spaCy tokenization and lemmatization documentations for more details.
If you are using Megagon Lab's Ginza model for Japanese, see the documentation here.
Here are all the spaCy models you can use in many languages (see the models section for more details):
- en_core_web_lg: spaCy large English
- ja_ginza_electra: Ginza Electra Japanese
- ja_core_news_lg: spaCy large Japanese
- fr_core_news_lg: spaCy large French
- zh_core_web_lg: spaCy large Chinese
- da_core_news_lg: spaCy large Danish
- nl_core_news_lg: spaCy large Dutch
- de_core_news_lg: spaCy large German
- el_core_news_lg: spaCy large Greek
- it_core_news_lg: spaCy large Italian
- lt_core_news_lg: spaCy large Lithuanian
- nb_core_news_lg: spaCy large Norwegian okmål
- pl_core_news_lg: spaCy large Polish
- pt_core_news_lg: spaCy large Portuguese
- ro_core_news_lg: spaCy large Romanian
- es_core_news_lg: spaCy large Spanish
It returns a list of tokens and their corresponding lemmas. Each token is an object made up of several elements. See below for the details.
HTTP Request
POST https://api.nlpcloud.io/v1/<model_name>/tokens
POST Values
These values must be encoded as JSON.
| Parameter | Type | Description |
|---|---|---|
| text | string | The sentence containing the tokens to extract. 350 tokens maximum. |
Output
This endpoint returns a tokens object containing an array of token objects.
Each token object contains the following:
| Key | Type | Description |
|---|---|---|
text |
string | The content of the extracted token. |
lemma |
string | The corresponding lemma of the extracted token. |
start |
int | The position of the 1st character of the token (starting at 0) |
end |
int | The position of the 1st character after the token |
index |
int | The position of the token in the sentence (starting at 1) |
ws_after |
boolean | Says whether there is a whitespace after the token, or not |
Translation
Input:
curl "https://api.nlpcloud.io/v1/nllb-200-3-3b/translation" \
-H "Authorization: Token <token>" \
-H "Content-Type: application/json" \
-X POST -d '{
"text":"John Doe has been working for Microsoft in Seattle since 1999.",
"source":"eng_Latn",
"target":"fra_Latn"
}'
import nlpcloud
client = nlpcloud.Client("nllb-200-3-3b", "<token>")
# Returns a json object.
client.translation("John Doe has been working for Microsoft in Seattle since 1999.", source='eng_Latn', target='fra_Latn')
require 'nlpcloud'
client = NLPCloud::Client.new('nllb-200-3-3b','<token>')
# Returns a json object.
client.translation("John Doe has been working for Microsoft in Seattle since 1999.", source: "eng_Latn", target: "fra_Latn")
import (
"net/http"
"github.com/nlpcloud/nlpcloud-go"
)
func main() {
client := nlpcloud.NewClient(&http.Client{}, nlpcloud.ClientParams{Model:"nllb-200-3-3b", Token:"<token>",
GPU:false, Lang:"", Async:false})
// Returns a Translation struct.
translatedText, err := client.Translation(nlpcloud.TranslationParams{
Text: "John Doe has been working for Microsoft in Seattle since 1999.",
Source: "eng_Latn",
Target: "fra_Latn",
})
...
}
const NLPCloudClient = require('nlpcloud');
const client = new NLPCloudClient({model:'nllb-200-3-3b',token:'<token>'})
// Returns an Axios promise with the results.
// In case of success, results are contained in `response.data`.
// In case of failure, you can retrieve the status code in `err.response.status`
// and the error message in `err.response.data.detail`.
client.translation({text:`John Doe has been working for Microsoft in Seattle since 1999.`,source:'eng_Latn',target'fra_Latn'}).then(function (response) {
console.log(response.data);
})
.catch(function (err) {
console.error(err.response.status);
console.error(err.response.data.detail);
});
require 'vendor/autoload.php';
use NLPCloud\NLPCloud;
$client = new \NLPCloud\NLPCloud('nllb-200-3-3b','<token>');
# Returns a json object.
echo json_encode($client->translation("John Doe has been working for Microsoft in Seattle since 1999.","eng_Latn","fra_Latn"));
Output:
{
"translation_text": "John Doe travaille pour Microsoft à Seattle depuis 1999."
}
This endpoint uses Facebook's NLLB 200 3.3B to translate text in 200 languages thanks to deep learning. Send a sentence, and the model will return a translation. If you don't know the language of your input text, you can let the model guess it for you (in that case, simply pass an empty string as a source language). This endpoint can also use your own custom model (replace the model name with the ID of your model in the URL).
Please note that NLLB works best with single sentences, so we recommend that you translate one sentence at a time. Ideally, you will want to split your text into sentences (in Python you can use the sent_tokenize() function from NLTK for example), then asynchronously send all your sentences to our API in parallel in order to maximize the throughput, and finally reassemble the results locally.
You can use translation if you need to use other models (Bart Large, etc.) in non-English languages. Just translate your text first before sending it to another model, and translate the result back to your original language.
Here is the model you can use:
- nllb-200-3-3b
Here are the supported languages and their corresponding codes:
| Language | Code |
|---|---|
| Acehnese (Arabic script) | ace_Arab |
| Acehnese (Latin script) | ace_Latn |
| Mesopotamian Arabic | acm_Arab |
| Ta’izzi-Adeni Arabic | acq_Arab |
| Tunisian Arabic | aeb_Arab |
| Afrikaans | afr_Latn |
| South Levantine Arabic | ajp_Arab |
| Akan | aka_Latn |
| Amharic | amh_Ethi |
| North Levantine Arabic | apc_Arab |
| Modern Standard Arabic | arb_Arab |
| Modern Standard Arabic (Romanized) | arb_Latn |
| Najdi Arabic | ars_Arab |
| Moroccan Arabic | ary_Arab |
| Egyptian Arabic | arz_Arab |
| Assamese | asm_Beng |
| Asturian | ast_Latn |
| Awadhi | awa_Deva |
| Central Aymara | ayr_Latn |
| South Azerbaijani | azb_Arab |
| North Azerbaijani | azj_Latn |
| Bashkir | bak_Cyrl |
| Bambara | bam_Latn |
| Balinese | ban_Latn |
| Belarusian | bel_Cyrl |
| Bemba | bem_Latn |
| Bengali | ben_Beng |
| Bhojpuri | bho_Deva |
| Banjar (Arabic script) | bjn_Arab |
| Banjar (Latin script) | bjn_Latn |
| Standard Tibetan | bod_Tibt |
| Bosnian | bos_Latn |
| Buginese | bug_Latn |
| Bulgarian | bul_Cyrl |
| Catalan | cat_Latn |
| Cebuano | ceb_Latn |
| Czech | ces_Latn |
| Chokwe | cjk_Latn |
| Central Kurdish | ckb_Arab |
| Crimean Tatar | crh_Latn |
| Welsh | cym_Latn |
| Danish | dan_Latn |
| German | deu_Latn |
| Southwestern Dinka | dik_Latn |
| Dyula | dyu_Latn |
| Dzongkha | dzo_Tibt |
| Greek | ell_Grek |
| English | eng_Latn |
| Esperanto | epo_Latn |
| Estonian | est_Latn |
| Basque | eus_Latn |
| Ewe | ewe_Latn |
| Faroese | fao_Latn |
| Fijian | fij_Latn |
| Finnish | fin_Latn |
| Fon | fon_Latn |
| French | fra_Latn |
| Friulian | fur_Latn |
| Nigerian Fulfulde | fuv_Latn |
| Scottish Gaelic | gla_Latn |
| Irish | gle_Latn |
| Galician | glg_Latn |
| Guarani | grn_Latn |
| Gujarati | guj_Gujr |
| Haitian Creole | hat_Latn |
| Hausa | hau_Latn |
| Hebrew | heb_Hebr |
| Hindi | hin_Deva |
| Chhattisgarhi | hne_Deva |
| Croatian | hrv_Latn |
| Hungarian | hun_Latn |
| Armenian | hye_Armn |
| Igbo | ibo_Latn |
| Ilocano | ilo_Latn |
| Indonesian | ind_Latn |
| Icelandic | isl_Latn |
| Italian | ita_Latn |
| Javanese | jav_Latn |
| Japanese | jpn_Jpan |
| Kabyle | kab_Latn |
| Jingpho | kac_Latn |
| Kamba | kam_Latn |
| Kannada | kan_Knda |
| Kashmiri (Arabic script) | kas_Arab |
| Kashmiri (Devanagari script) | kas_Deva |
| Georgian | kat_Geor |
| Central Kanuri (Arabic script) | knc_Arab |
| Central Kanuri (Latin script) | knc_Latn |
| Kazakh | kaz_Cyrl |
| Kabiyè | kbp_Latn |
| Kabuverdianu | kea_Latn |
| Khmer | khm_Khmr |
| Kikuyu | kik_Latn |
| Kinyarwanda | kin_Latn |
| Kyrgyz | kir_Cyrl |
| Kimbundu | kmb_Latn |
| Northern Kurdish | kmr_Latn |
| Kikongo | kon_Latn |
| Korean | kor_Hang |
| Lao | lao_Laoo |
| Ligurian | lij_Latn |
| Limburgish | lim_Latn |
| Lingala | lin_Latn |
| Lithuanian | lit_Latn |
| Lombard | lmo_Latn |
| Latgalian | ltg_Latn |
| Luxembourgish | ltz_Latn |
| Luba-Kasai | lua_Latn |
| Ganda | lug_Latn |
| Luo | luo_Latn |
| Mizo | lus_Latn |
| Standard Latvian | lvs_Latn |
| Magahi | mag_Deva |
| Maithili | mai_Deva |
| Malayalam | mal_Mlym |
| Marathi | mar_Deva |
| Minangkabau (Arabic script) | min_Arab |
| Minangkabau (Latin script) | min_Latn |
| Macedonian | mkd_Cyrl |
| Plateau Malagasy | plt_Latn |
| Maltese | mlt_Latn |
| Meitei (Bengali script) | mni_Beng |
| Halh Mongolian | khk_Cyrl |
| Mossi | mos_Latn |
| Maori | mri_Latn |
| Burmese | mya_Mymr |
| Dutch | nld_Latn |
| Norwegian Nynorsk | nno_Latn |
| Norwegian Bokmål | nob_Latn |
| Nepali | npi_Deva |
| Northern Sotho | nso_Latn |
| Nuer | nus_Latn |
| Nyanja | nya_Latn |
| Occitan | oci_Latn |
| West Central Oromo | gaz_Latn |
| Odia | ory_Orya |
| Pangasinan | pag_Latn |
| Eastern Panjabi | pan_Guru |
| Papiamento | pap_Latn |
| Western Persian | pes_Arab |
| Polish | pol_Latn |
| Portuguese | por_Latn |
| Dari | prs_Arab |
| Southern Pashto | pbt_Arab |
| Ayacucho Quechua | quy_Latn |
| Romanian | ron_Latn |
| Rundi | run_Latn |
| Russian | rus_Cyrl |
| Sango | sag_Latn |
| Sanskrit | san_Deva |
| Santali | sat_Olck |
| Sicilian | scn_Latn |
| Shan | shn_Mymr |
| Sinhala | sin_Sinh |
| Slovak | slk_Latn |
| Slovenian | slv_Latn |
| Samoan | smo_Latn |
| Shona | sna_Latn |
| Sindhi | snd_Arab |
| Somali | som_Latn |
| Southern Sotho | sot_Latn |
| Spanish | spa_Latn |
| Tosk Albanian | als_Latn |
| Sardinian | srd_Latn |
| Serbian | srp_Cyrl |
| Swati | ssw_Latn |
| Sundanese | sun_Latn |
| Swedish | swe_Latn |
| Swahili | swh_Latn |
| Silesian | szl_Latn |
| Tamil | tam_Taml |
| Tatar | tat_Cyrl |
| Telugu | tel_Telu |
| Tajik | tgk_Cyrl |
| Tagalog | tgl_Latn |
| Thai | tha_Thai |
| Tigrinya | tir_Ethi |
| Tamasheq (Latin script) | taq_Latn |
| Tamasheq (Tifinagh script) | taq_Tfng |
| Tok Pisin | tpi_Latn |
| Tswana | tsn_Latn |
| Tsonga | tso_Latn |
| Turkmen | tuk_Latn |
| Tumbuka | tum_Latn |
| Turkish | tur_Latn |
| Twi | twi_Latn |
| Central Atlas Tamazight | tzm_Tfng |
| Uyghur | uig_Arab |
| Ukrainian | ukr_Cyrl |
| Umbundu | umb_Latn |
| Urdu | urd_Arab |
| Northern Uzbek | uzn_Latn |
| Venetian | vec_Latn |
| Vietnamese | vie_Latn |
| Waray | war_Latn |
| Wolof | wol_Latn |
| Xhosa | xho_Latn |
| Eastern Yiddish | ydd_Hebr |
| Yoruba | yor_Latn |
| Yue Chinese | yue_Hant |
| Chinese (Simplified) | zho_Hans |
| Chinese (Traditional) | zho_Hant |
| Standard Malay | zsm_Latn |
| Zulu | zul_Latn |
HTTP Request
POST https://api.nlpcloud.io/v1/nllb-200-3-3b/translation
POST Values
These values must be encoded as JSON.
| Key | Type | Description |
|---|---|---|
text |
string | The sentence that you want to translate. 256 tokens maximum in synchronous mode and 1 million tokens maximum in asynchronous mode. |
source |
string | The language of the input text. If is an empty string, the model will try to automatically detect the input language, but if you know the language it is recommended to explicitly mention it. |
target |
string | The language of the translated text. |
Output
This endpoint returns a JSON object containing the following elements:
| Key | Type | Description |
|---|---|---|
translation_text |
string | The translation of your text |
Fine-tuning
This is possible to train/fine-tune your own generative models on NLP Cloud and use them in production. Fine-tuning is the best way to get the most advanced results. Please note that fine-tuning is not suited to "feed" a model with new knowledge. In that case, semantic search is more suited.
You can fine-tune the following models:
- Dolphin
- Yi 34B
- Mixtral 8x7B
Subscribe to a fine-tuning plan and then go to the Fine-Tuning section in your dashboard:
First upload your own dataset. It all happens in your dashboard.
If your dataset is very heavy, you can compress it as a ZIP archive and upload your ZIP file. There is no limit regarding the size of the dataset.
You don't necessarily have to create the dataset by yourself since many great open-source datasets already exist. Maybe one of them is perfect for your use case? An advanced list of open-source datasets can be found on the Hugging Face website.
If you are unsure about which data you should use for your fine-tuning, please contact us so we can advise.
You can upload a new dataset, and start a new fine-tuning based on it, as many times as you want. When the new fine-tuning is finished, we replace your existing model with the new one. It causes a short downtime (around 10 minutes). If you don't want your previous model to be deleted, or if you want to avoid the short downtime, you should launch several fine-tunings in parallel.
Once the fine-tuning is finished and your model is deployed, you will be informed by email, and you will get a dedicated API URL for your new fine-tuned model.
Dataset Format
You can fine-tune generative models for text generation and any NLP task based on text generation (paraphrase, summarization, classification, sentiment analysis, chatbots, code generation, etc.).
Your dataset should be a text file (.txt) or a zip archive (.zip) containing a text file. It doesn't need to follow any specific formatting, except that you should add <|endoftext|> at the end of each example.
If you are coming from OpenAI, you can also use your OpenAI dataset, as a CSV (.csv) or a JSONL (.jsonl) file (you can also zip the file if needed). This file should contain the 2 following columns or keys:
- prompt
- completion
Each example should not exceed 1024 tokens if you are on the Basic Fine-Tuning plan, or 2048 tokens if you are on the Advanced Fine-Tuning plan.
The size of your dataset depends on your use case. In general, fine-tuning Dolphin requires relatively few examples (compared to traditional NLP fine-tuning). Here are a couple of guidelines, depending on your use case:
- Classification: at least 100 examples per class. For example, if you want to create 6 categories, you will need at least 600 examples.
- Sentiment Analysis: at least 300 examples
- Content Generation (chatbots, summarization, paraphrasing, blog post generation, code generation, NER, ...): at least 500 examples
In general, the more examples the better. But keep in mind that if at some point you include too many examples in your dataset without enough diversity, your model might suffer from overfitting, meaning that your model will always produce results that are too close from your original examples.
If you are unsure about the format or the size of your dataset, please contact us so we can advise.
Dataset Examples
Here are examples of how you could format your dataset for various use cases (these are only suggestions of course). Basically you can apply the same technique that you would use during few-shot learning. Note that the trailing ### token is not compulsory. We recommend to add it at the end of all your examples so the model will add it to every response. Then you can conveniently use end_sequence="###" in your requests in production to make sure that the model does not generate more text than wanted. Most of the time, after a fine-tuning, Dolphin does not generate more text than necessary, but it still occasionnally happens, even when properly adding <|endoftext|> at the end of your examples, so thanks to this parameter you will be able to force Dolphin to stop the text generation once your answer is generated.
Dataset for Short Story Generation
Let's say you want to teach your model how to generate short stories about specific topics. You could build a dataset like the following (many more examples would be needed of course):
| love: I went out yesterday with my girlfriend, we spent an amazing moment. |
| <|endoftext|> |
| adventure: We stayed one week in the jungle without anything to eat, it was tough... |
| <|endoftext|> |
| love: I fell in love with NLP Cloud. My life has changed since I met them! |
| <|endoftext|> |
Dataset for Sentiment Analysis
A fine-tuning dataset for sentiment analysis could look like this:
| [Message]: Support has been terrible for 2 weeks... [Sentiment]: Negative ### |
| <|endoftext|> |
| [Message]: I love your API, it is simple and so fast! [Sentiment]: Positive ### |
| <|endoftext|> |
| [Message]: Dolphin has been released 2 months ago. [Sentiment]: Neutral ### |
| <|endoftext|> |
Dataset for NER (Entity Extraction)
| [Sentence]: My name is Julien and I work for NLP Cloud as a Chief Technical Officer. [Position]: Chief Technical Officer [Company]: NLP Cloud ### |
| <|endoftext|> |
| [Sentence]: Hi, I am a marketing assistant at Microsoft. [Position]: marketing assistant [Company]: Microsoft ### |
| <|endoftext|> |
| [Sentence]: John was the CEO of AquaFun until 2020. [Position]: CEO [Company]: AquaFun ### |
| <|endoftext|> |
Dataset for Text Classification
| [Sentence]: I love skiing, rugby, and boxing. These are great for the body and the mind. [Category]: Sport ### |
| <|endoftext|> |
| [Sentence]: In order to cook a pizza you need flour, tomatoes, ham, and cheese. [Category]: Food ### |
| <|endoftext|> |
| [Sentence]: The Go programming language is a statically typed language, perfect for concurrent programming. [Category]: Programming ### |
| <|endoftext|> |
Dataset for Question Answering
| [Context]: NLP Cloud was founded in 2021 when the team realized there was no easy way to reliably leverage NLP in production. [Question]: When was NLP Cloud founded? [Answer]: 2021 ### |
| <|endoftext|> |
| [Context]: NLP Cloud developed their API by mid-2020 and they added many pre-trained open-source models since then [Question]: What did NLP Cloud develop? [Answer]: API ### |
| <|endoftext|> |
| [Context]: The main challenge with Dolphin is memory consumption. Using a GPU plan is recommended. [Question]: Which plan is recommended for Dolphin? [Answer]: a GPU plan ### |
| <|endoftext|> |
Dataset for Code Generation
| [Question]: Fetch the companies that have less than five people in it. [Answer]: SELECT COMPANY, COUNT(EMPLOYEE_ID) FROM Employee GROUP BY COMPANY HAVING COUNT(EMPLOYEE_ID) < 5; ### |
| <|endoftext|> |
| [Question]: Show all companies along with the number of employees in each department [Answer]: SELECT COMPANY, COUNT(COMPANY) FROM Employee GROUP BY COMPANY; ### |
| <|endoftext|> |
| [Question]: Show the last record of the Employee table [Answer]: SELECT * FROM Employee ORDER BY LAST_NAME DESC LIMIT 1; ### |
| <|endoftext|> |
Dataset for Paraphrasing
| [Original]: Algeria recalled its ambassador to Paris on Saturday and closed its airspace to French military planes a day later after the French president made comments about the northern Africa country. [Paraphrase]: Last Saturday, the Algerian government recalled its ambassador and stopped accepting French military airplanes in its airspace. It happened one day after the French president made comments about Algeria. ### |
| <|endoftext|> |
| [Original]: President Macron was quoted as saying the former French colony was ruled by a "political-military system" with an official history that was based not on truth, but on hatred of France. [Paraphrase]: Emmanuel Macron said that the former colony was lying and angry at France. He also said that the country was ruled by a "political-military system". ### |
| <|endoftext|> |
| [Original]: The diplomatic spat came days after France cut the number of visas it issues for citizens of Algeria and other North African countries. [Paraphrase]: Diplomatic issues started appearing when France decided to stop granting visas to Algerian people and other North African people. ### |
| <|endoftext|> |
Dataset for Chatbot / Conversational AI
The trick here is that a discussion should be split into several examples (one per AI response):
| This is a discussion between a [human] and a [robot]. The [robot] is very nice and empathetic. [human]: Hello nice to meet you. [robot]: Nice to meet you too. ### |
| <|endoftext|> |
| This is a discussion between a [human] and a [robot]. The [robot] is very nice and empathetic. [human]: Hello nice to meet you. [robot]: Nice to meet you too. ### [human]: How is it going today? [robot]: Not so bad, thank you! How about you? ### |
| <|endoftext|> |
| This is a discussion between a [human] and a [robot]. The [robot] is very nice and empathetic. [human]: Hello nice to meet you. [robot]: Nice to meet you too. ### [human]: How is it going today? [robot]: Not so bad, thank you! How about you? ### [human]: I am ok, but I am a bit sad... [robot]: Oh? Why that? ### |
| <|endoftext|> |
Fine-tuning your own chatbot works very well to adapt the tone of your chatbot. For example you can create specifc characters and personalities thanks to fine-tuning. However it does not work so well if you want to inject specific knowledge into your chatbot. In order to create a chatbot that will correctly answer questions on your own knowledge, you will need to mix both semantic search and generative AI. Please read this article: Question Answering On Domain Knowledge With Semantic Search And Generative AI.
Dataset for Product and Ad Descriptions
| [Keywords]: shoes, women, $59 [Sentence]: Beautiful shoes for women at the price of $59. ### |
| <|endoftext|> |
| [Keywords]: trousers, men, $69 [Sentence]: Modern trousers for men, for $69 only. ### |
| <|endoftext|> |
| [Keywords]: gloves, winter, $19 [Sentence]: Amazingly hot gloves for cold winters, at $19. ### |
| <|endoftext|> |
Fine-tuning Validation
By default you cannot upload a validation dataset. Please contact support if you want to use one.
Assessing the accuracy of generative models is hard because these models are non-deterministic, meaning that for the same input you can get different outputs.
If you are fine-tuning a generative model for a use-case that produces non-deterministic results (blog post generation, summarization, paraphrasing, chatbots, product description and ad generation...), you should not upload a validation dataset as the results would not mean anything. For such use cases, the best solution would be for you to manually run a batch of examples on your fine-tuned models, once they are deployed. If you want to make your models comparison easier, you could set a low top p or a low temperature during your tests, as they make results much more deterministic.
If you are fine-tuning a generative model for a use-case that does produce deterministic results (text classification, entity extraction, keywords/keyphrases extraction, question answering, intent classification, code generation...), you might want to upload a validation dataset that will help you automatically assess the quality of your new fine-tuned model. But this is optional.
Sensitive Applications
No data sent to our API is stored on our servers, but sometimes this is not enough.
Here are 3 advanced solutions we propose for sensitive applications.
Specific Region
For legal reasons you might want to make sure that the data you send is processed in a specific region of the world. It can be a specific continent (e.g. North America, Europe, Asia,...), or a specific country (e.g. US, France, Germany, ...).
If that is the case, please contact us at [email protected].
Specific Cloud Provider
You might want to avoid a specific cloud provider, or proactively choose a cloud provider (eg. AWS, GCP, OVH, Scaleway...).
If that is the case, please contact us at [email protected].
On-Premise
If you cannot afford to send any data to NLP Cloud for confidentiality reasons (e.g. medical applications, financial applications...) you can deploy our models on your own in-house infrastructure.
If that is the case, please contact us at [email protected].
Rate Limiting
Rate limiting depends on the plan you subscribed to. See more details on the pricing page.
If you reach such a limit, the API will return a 429 HTTP error. In that case, you should retry your request a bit later.
Teams
In your dashboard, you can create an organization and invite team members to join the organization.
Each team member is given a role: Admin, Manager, or Reader. Depending on his role, a user has access to different features:
| Admin | Manager | Reader | |
|---|---|---|---|
| Access API | Yes | Yes | Yes |
| Create a fine-tuned model | Yes | Yes | No |
| Create a semantic search model | Yes | Yes | No |
| Install a custom model | Yes | Yes | No |
| Control pay-as-you-go limits | Yes | Yes | No |
| Manage subscription | Yes | No | No |
Errors
The NLP Cloud API uses the following error HTTP codes:
| Code | Meaning |
|---|---|
400 |
Bad Request -- Your request is invalid. |
401 |
Unauthorized -- Your API token is wrong. |
402 |
Payment Required -- You are trying to access a resource that is only accessible after payment. |
403 |
Forbidden -- You do not have the sufficient rights to access the resource. Please make sure you subscribed to the proper plan that grants you access to this resource. |
404 |
Not Found -- The specified resource could not be found. |
405 |
Method Not Allowed -- You tried to access a resource with an invalid method. |
406 |
Not Acceptable -- You requested a format that isn't json. |
413 |
Request Entity Too Large -- The piece of text that you are sending it too large. Please see the maximum sizes in the documentation. |
422 |
Unprocessable Entity -- Your request is not properly formatted. Happens for example if your JSON payload is not correctly formatted, or if you omit the "Content-Type: application/json" header. |
429 |
Too Many Requests -- You made too many requests in a short while, please slow down. |
500 |
Internal Server Error -- Sorry, we had a problem with our server. Please try again later. |
502 |
Bad Gateway -- Sorry, our reverse proxy was not able to contact the model you're requesting. Please try again later. |
503 |
Service Unavailable -- Sorry, the model you are requesting had a temporary issue. Please try again later. The error is returned together with a Retry-After header, mentioning the number of seconds you should wait before trying again. |
504 |
Gateway Timeout -- Sorry, the model you are requesting is temporarily overloaded. Please try again later. |
520 |
Unknown Error -- Sorry, an unknown error occurred. It often happens when your request is taking too long to return (more than 60 seconds), in case of text generation for example. Please try again with a shorter request. |
522 |
Connection Timeout -- Sorry, your request timed out. It happens when your request is taking too long to return (more than 60 seconds), in case of text generation for example. Please try again with a shorter request. |
524 |
Timeout Error -- Sorry, your request timed out. It happens when your request is taking too long to return (more than 60 seconds), in case of text generation for example. Please try again with a shorter request. |
If you experience any problem, please do not hesitate to contact us at [email protected].